
《Redis 深度历险》读书笔记
想学就学,哪要那么多理由
其实很早以前就有看 Redis 的计划,当时是因为对非关系型数据库感兴趣。但又觉得暂时没啥能用的到 Redis 地方。 这学期想明白了:知识反正学到了,就是自己的。哪管它目前用不用的上。 9 月 9 日到学校图书馆借了本《Redis 深度历险》,今天刚好一个月看完。除了第五章关于 Redis 的底层源码我目前还看得挺懵逼的,别的章节确实让我学了不少东西! 因此强烈安利各位想学 Redis 的小伙伴去看看这本**《Redis 深度历险》**,全彩印刷,图文并茂,作者描述很多概念时写得是通俗易懂,一口气看下来酣畅淋漓,真的很佩服! 那么下面就来写一下我个人觉得比较重要的一些东西,同时记录一下自己的看法。
5 种基础的数据结构
Redis 中有 5 种最基础的数据结构:string list hash set zset
string
这个其实就是最简单的键值对,其中 value 是字符串形式的:
set name john
set wife mashiro
get name
mget name wife # 返回一个列表
计数
若 value 的值是一个整数,可以通过incr以及incrby来进行自增操作。
set money 10000
incr money # 10001
incrby money 1000 # 11001
需要注意的是关于 Redis 字符串底层内存分配的情况。Redis 是使用 C 语言编写,使用第三方库 jamalloc(默认) 或 tcmalloc 来管理内存。
Redis 字符串叫做SDS,即Simple Dynamic String,在源码中是一个结构体:
struct SDS<T>{
T capacity; // 数组容量
T len; // 数组长度
byte flags; // 特殊标志位,不用管
byte[] content; // 数组内容
}
其中content数组存储着字符串的内容,capacity数组容量,指的是所分配给数组的长度,len数组长度才是其实容量。capacity一般要高于实际字符串长度len。**当字符串长度小于 1MB 时,扩容都是加倍现有空间。如果字符串长度超过 1MB,扩容时一次只会多扩 1MB 的空间。**同时需要注意的是,字符串的最大长度为 512MB。
另外一点比较有意思的是,上述 SDS 结构体使用了泛型 T,从而能指定capacity与len的类型。这是因为 Redis 为了对内存做极致优化,不同长度的字符串使用不同的结构体表示。比如当字符串较短时,capacity与len可以使用short和byte类型,而非全都是int类型。
很多人都在黑 Golang 没有泛型,之前一直不太明白泛型是个什么概念,应用场景是什么,看了 Redis 的 SDS 后,明白了不少。
list
List (列表)相当于一个双向链表,这也使得其插入与删除操作非常快,但索引定位很慢。
我们可以使用rpush lpush rpop lpop来从列表的两端插入和取出元素。从而可以实现队列、栈两种数据结构。
右进左出:队列
rpush wife mashiro asuna emiria
llen wife # 3
lpop wife # mashiro
lpop wife # asuna
右进右出:栈
rpush wife mashiro asuna emiria
rpop wife # emiria
rpop wife # asuna
当列表元素较少时,Redis 会采用ziplist(压缩列表)的结构;当数据量比较多时,会改为quicklist(快速列表)的结构,quicklist其实就是将一个双向链表,其中的节点是一个个ziplist。
hash
hash 就是我们常见的键值对哈希表。
hset wife mashiro "sakurasou"
hset wife asuna "sao"
hset wife emiria "re0"
hlen wife # 3
hgetall wife # 返回所有的键和值
set
set 我感觉像一个字典,其中的值是无序的,唯一的。
sadd wife mashiro
sadd wife asuna
sadd wife emiria
smembers wife # 返回所有数据(无序)
sismember wife asuna # True, 查询 value 是否存在
sismember wife alice # False
scard wife # 获取长度
spop wife # 弹出一个
zset
zset是 Redis 中十分有特色的一个数据结构。它可以看做是一个set,因此他的元素是无序的,唯一的。而他的每个元素除了有 value 外,还有 score 这个值来指定权重。因此可以按照权重的区间来筛选数据。
zadd wife 1 "mashiro"
zadd wife 0.9 "asuna"
zadd wife 0.8 "emiria"
zrange wife 0 -1 # 按 score 排序列出,其中的 0 -1 为 score 的范围
zrevrange wife 0 -1 # 按 score 逆序列出
scard wife # 获取长度
zscore wife "asuna" # 获取指定元素的 value
zrank wife "mashiro" # 获取指定元素的排名
zrangebyscore wife 0 0.95 # 按照区间筛选
zrangebyscore wife -inf 0.95 # -inf 为无限小
zrem wife "emiria" # 删除元素
分布式锁
当说起 Redis 能干什么时,大多数人都只会回答说 Redis 可以用来做缓存。只有很少的人知道 Redis 还可以来做分布式锁。
Redis 中的setnx指令(set if not exists),可以用来加锁。当成功加锁时,会返回OK,若锁已存在,则会返回nil。之后可以使用del删除这个 key 从而实现释放锁。若程序中间出现了异常,使得del指令永远不会被执行,从而会导致死锁。这时我们可以执行expire命令来给 key 设置过期时间,超时后即被自动释放。
综上所述:
setnx mylock true
expire mylock 10
# ...... Code here ......
del mylock
但是问题在于setnx和expire是两条指令而不是原子指令,若setnx执行成功后,expire未执行成功,那么也会导致死锁。在 Redis 2.8 之后,set指令加入了扩展参数,使得setnx和expire指令可以一起执行:
set mylock true ex 10 nx
# ...... Code here ......
del mylock
超时问题
若上述锁的超时时间设置的过小,导致第一个线程主要逻辑代码还没执行完,锁就已经到期被自动释放了。之后第二个线程持有了这把锁,这时第一个线程执行到了del mylock的位置,便把第二个线程锁持有的锁给释放了。这就是超时问题。
除了用 Lua 脚本来解决之外,我们可以将锁的 value 由true改为一个随机数,这样这个锁就与当前线程“绑定”了,当第一个限制执行del mylock时,他要先判断当前锁的 value,发现和自己的随机数不匹配,因此就不会执行释放锁。
锁冲突处理
当尝试加锁不成功时,一般有如下三种策略来进行处理:
- 直接抛出异常 如果加锁操作是由用户发起的请求,则可以向用户抛出一个异常(比如弹一个错误的对话框),然后引导用户重新发起请求。本质上是对当前请求的放弃,由用户决定是否重新发起请求。
- sleep
睡一小会儿再重试。但是
sleep会阻塞当前消息处理线程,导致后续消息处理出现延迟。如果经常遇到锁冲突的情况,则不推荐使用sleep。如果是因为死锁导致的加锁不成功,线程会彻底堵死。 - 延时队列 延时队列是使用 Redis 的 List 数据结构,可以实现异步消息队列,将当前有冲突的请求放到另一个队列延后处理。其实关于消息队列这一块,我其实了解的并不多,只听说过 Kafka 的名字,了解些生产者消费者啥的而已。嘛,这也是以后要去学的一个东西呀!
Bitmap
这是我很喜欢的一个数据结构——Bitmap(位图)。它存储的是一个 bit 数组,其中元素的值只有 0 和 1。**比较典型的应用场景就是用户的每日签到。**我在学习过程中就用 Golang + Redis 实现了一个用户每日签到的程序。
我们可以用每个 bit 代表用户的每一天,0 或 1 代表用户签到与否。那么一个用户,一年 365 天下来的签到数据总共只需要 365 bits,大约 46 字节!!这个真的是很小很小了。只需 1 MB 的内存就可以容纳两万多人一年的签到数据!
Bitmap 其实不是特殊的数据结构,它的内容就是普通的 String(字符串),即 byte 数组。因此可以使用get set 来获取整个位图的内容,也可以使用getbit setbit来对单个 bit 进行处理。
setbit signin 1 1
setbit signin 5 1
bitcount signin # 可以获取总签到天数
bitfield signin get u31 0 # 从第一位(0)开始取 31 位,结果是无符号整数(u)
HyperLogLog
这个数据结构的一个典型应用——**计算网页中一个页面的 UV(Unique Visitor)数量。**对于统计一个网页的 PV 来说,我们只需要一收到用户的请求,就将 PV 值加一即可。但是 UV 不同,它表示的是独立访客数量,因此同一个用户多次访问只能算作一次。也就是说我们需要记录用户的信息,并且去重。当访问的用户信息达到千万级别时,再用 set 集合来实现就显得十分浪费空间了。因此,就有了 HyperLogLog。 值得注意的是,HyperLogLog 统计出来的数量与真实的数量大概存在 0.81% 的误差。这也算是为了速度牺牲准确性。然而我们所需要的统计数据往往也不需要十分精确,有误差存在是可以接受的。 HyperLogLog 的使用方法很简单:
pfadd mainpage_pv user1
pfadd mainpage_pv user2
pfadd mainpage_pv user3
......
pfcount mainpage_pv
PS:这里的user1等等可以换成发起请求的用户的 IP。
HyperLogLog 数据结构会占据 12 KB 的存储空间,因此不适合统计单个用户相关的数据。
布隆过滤器
HyperLogLog 数据结构只能计算数据的数量,而没办法得知某个元素是否在数据里。 有这样一个典型的场景:新闻客户端给用户推送新闻,会将用户已经看过的新闻过滤掉。这时就需要知道该条新闻用户是否看过。这里就可以用到布隆过滤器。它其实和 HyperLogLog 一样,都是不怎么精确的——它会对某些不存在的元素产生误判,认为其实存在的。这也就导致可能有些新闻用户并没有看过,但布隆过滤器却认为用户已经看过了,便不再推送。 一言以盖之:当布隆过滤器说某个值存在,这个值可能不存在;当它说某个值不存在时,这个值肯定不存在。(因为不存在的值可能与已有的值相似,从而造成误判) Redis 中的布隆过滤器是通过插件在 Redis 4.0 之后才出现的。可以直接 Docker 一把梭:
docker run -dt --name redis_bloom redislabs/rebloom
bf.add mainpage_pv user1
bf.add mainpage_pv user2
bf.add mainpage_pv user3
......
bf.exists mainpage_pv user1
布隆过滤器默认配置下的误判率大约在 1% 左右。它提供了bf.reserve指令可供我们自定义它的参数。我们可以在bf.add之前使用该指令。
使用方法:
bf.reserve key error_rate initial_size
error_rate错误率,默认值为 0.01,设置的越大所需要的空间越多。initial_size预计放入的元素数量,实际数量超出这个数值后会导致误判率升高。实际使用中需要加上一定的冗余空间避免意外情况的发生。
其它应用
- 爬虫系统中,对于爬取到的 URL 进行去重,从而确定是否需要爬取。
- 邮件系统的垃圾邮件过滤功能
限流
简单限流
限流,即控制流量,可以起到避免垃圾请求、恶意发帖、回复等行为。
简单限流的实现是使用zset这个数据结构。用户的每次操作都会创建一条数据,score为当前的时间戳。之后通过zremrangebyscore来删去时间窗口范围外的数据,然后使用zcard来获取总共行为的数据数量;若小于限制数量,则予以放行。
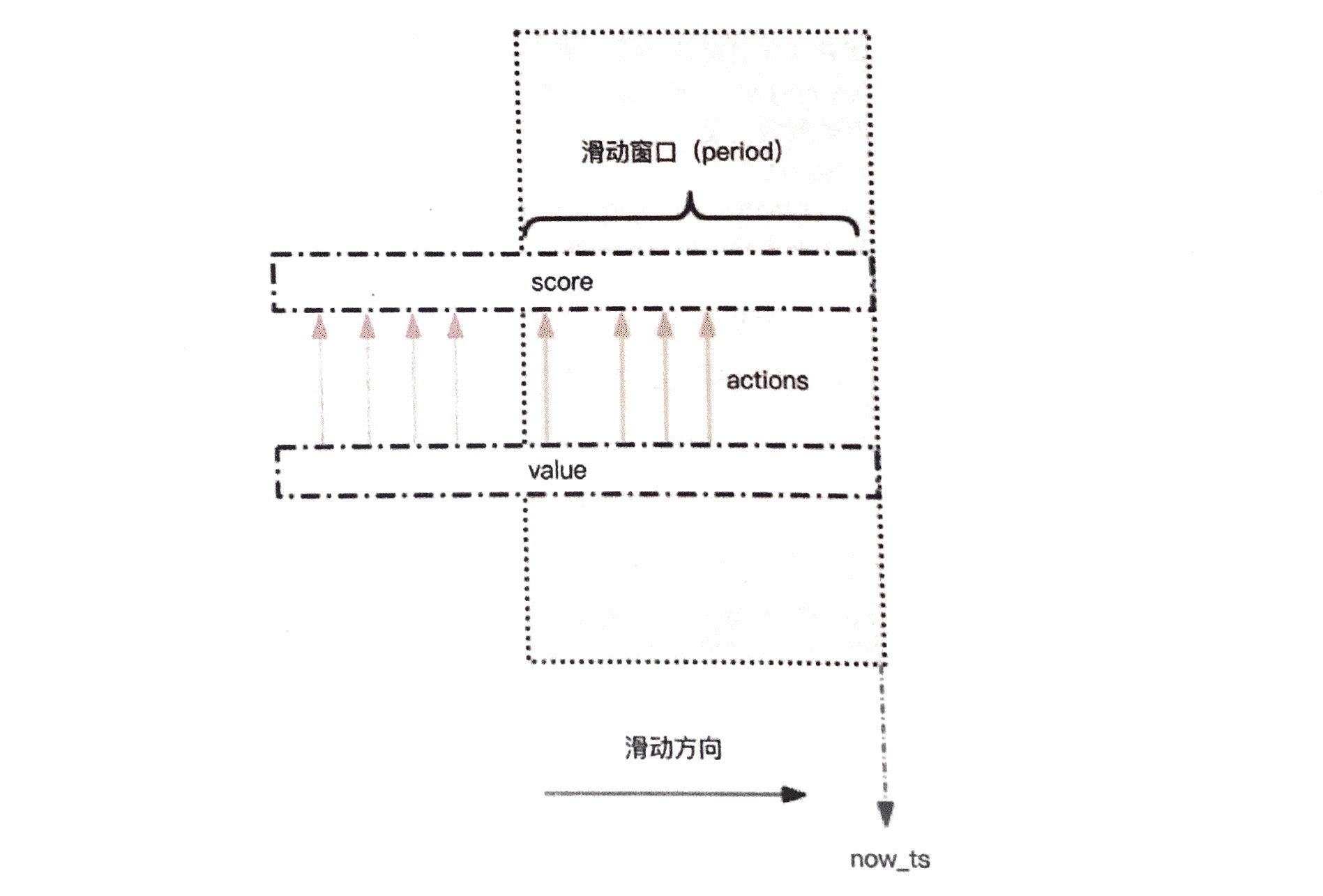 说起来可能有些绕,我用 Golang 写了一个 demo:
说起来可能有些绕,我用 Golang 写了一个 demo:
client := redis.NewClient(&redis.Options{
Addr: "localhost:6379",
DB: 0,
})
r := gin.Default()
r.GET("/message", func(c *gin.Context) {
period := 15 // second
maxCount := 5
key := "message_john"
// Remove the expire data
client.ZRemRangeByScore(key, "0", strconv.Itoa(int(time.Now().UnixNano() - int64(period * 1000 * 1000 * 1000))))
// Get the range count
count := client.ZCard(key)
fmt.Println(count.Val())
// Check the time period
if int(count.Val()) > maxCount - 1 {
c.JSON(403, gin.H{
"message": "You're not allowed to access!",
})
return
}
value := redis.Z{
Score: float64(time.Now().UnixNano()),
Member: time.Now().UnixNano(),
}
client.ZAdd(key, &value)
c.JSON(200, gin.H{
"message": "Hello John!",
})
})
_ = r.Run()
Score以及ZRemRangeByScore中的时间格式,需要为毫秒或纳秒时间戳。
若为秒时间戳的话,用户在一秒内的多次请求,只会被记录一次。即会绕过限流。漏斗限流
漏斗限流模拟的就是漏斗的原理:一个漏斗的容量是有限的,当漏嘴被堵住时,就可以往里面灌水。当漏斗变满时,就无法再装水了。这时将漏嘴打开,水会往下流,流走的部分又能继续灌水。 若放水速率大于灌水速率,漏斗将永远不会满;若灌水速度大于放水速度,漏斗满了之后就需要停止灌水,放水腾出新的空间。 Redis 4.0 提供限流模块——Redis-Cell。该模块也使用了漏斗算法。 可以到 https://github.com/brandur/redis-cell 下载安装此模块。
GeoHash
这是 Redis 3.2 版本以后增加的地理位置 Geo 模块。这个我觉得确实蛮接“地”气的。 意味着我们可以使用 Redis 来实现滴滴打车,摩拜单车等实时定位查询附近的功能了。之前我也曾做过这样的功能,因为地球是椭圆形的,所以经纬度之间距离的换算不能单纯的套用勾股定理。需要按一定的系数加权后再求和。 GeoHash 是默认装载在 Redis 内的模块,下面我只按照书上的例子记录一下它的基本使用方式:
添加
geoadd company 116.48105 39.99794 juejin
geoadd company 116.514203 39.905409 ireader
geoadd company 116.489033 40.007669 meituan
距离计算
geodist company juejin ireader km
注意最后面需要带上距离单位。距离单位可以是:m(米)、km(千米)、ml(英里)、ft(尺)。
获取元素的位置
geopos company juejin
附近的元素
这应该就是最为常用的指令了,给定一个坐标和范围,然后查找它附近的元素。
georadiusbymember company ireader 20 km count 3 asc # 距离 20km 的元素,按距离顺序正排,且不会排除自身
georadiusbymember company ireader 20 km withcoord withdist withhash count 3 asc
# withcoord 返回结果会带上匹配位置的经纬度
# withdist 返回结果会带上与匹配位置之间的距离
# withhash 返回结果会带上匹配位置的 hash 值
Redis 的 Geo 数据结构,是全部被存放在一个 zset 集合中的。当处于 Redis 集群环境并且要进行迁移时,如果单个 key 的数据量超过 1MB,则会导致集群迁移时出现卡顿,从而影响业务。因此需要适当的对 Geo 的数据内容进行拆分。
scan
scan指令用来查找 Redis 中的 key。与 keys指令不同的是,scan可以限制查询的数量。
scan 0 match key99* count 1000
scan指令的入参有三个:
cursor整数值,相当于一个游标key正则表达式limit限定匹配数量
这里需要注意的是cursor这个东西。当我们使用scan查找时并指定了limit时,会发现返回的结果往往远没有limit中的这么多。同时返回结果中还会有一个整数,它会作为下一次遍历的cursor,一直到返回的cursor为 0 时,即表示已经遍历完了全部数据。
这里要注意的是:有时scan返回的数据为空,但cursor不为 0,则代表还未遍历匹配完,我们还需要继续使用scan指令。
这是因为 Redis 所有的 key 都是存储在一个大的字典中的,数据结构如图:
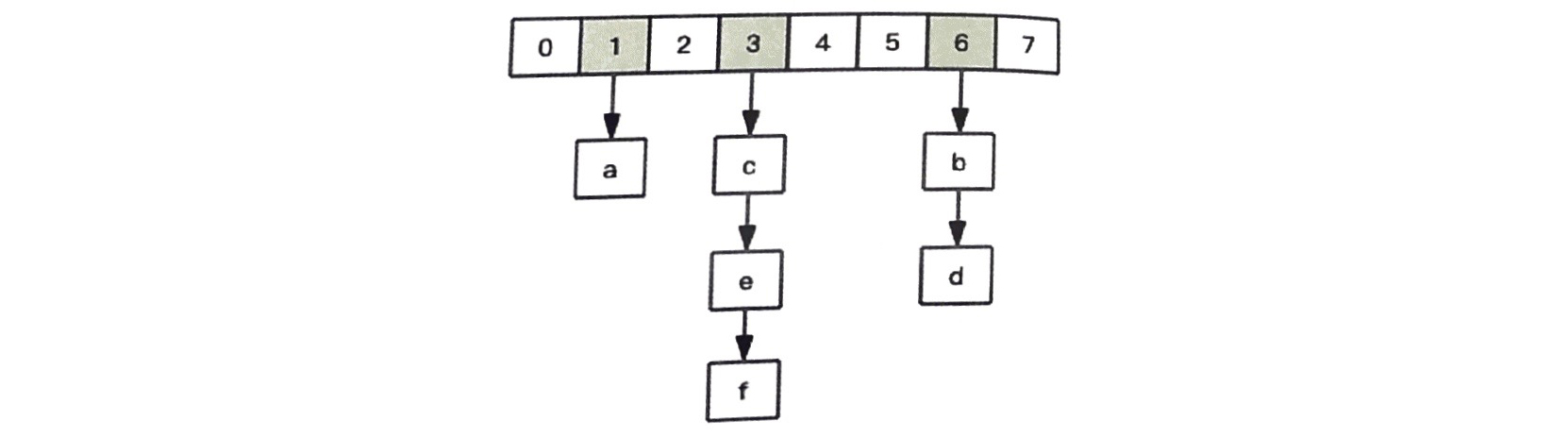
它是一个一位数组,下面的第二维挂着链表。第一维数组的大小总是 2^n,扩容一次数组,大小空间加倍,即 2^(n+1)。
scan指令的游标就是第一维数组的位置索引,称作slot(槽)。每个槽下面的链表可长可短,还有的可能是空的。每一次的scan遍历,都是在遍历limit数量的槽位上挂载的链表里的数据。因此就出现了每次陆陆续续地返回的情况。
RESP
这是我觉得很有意思也很奇妙的一个东西。RESP(Redis Serialization Protocol)Redis 序列化协议,是 Redis 服务端、客户端之间的通信协议。它是一个文本协议而非二进制协议,且过程异常简单,解析性能极好,可读性强,因此也有很多开源项目选用 RESP 作为通信协议。
Redis 协议将传输的结构数据分为 5 种最小的单元类型,单元结束时统一加上回车换行符号\r\n。
- 单行字符串以
+符号开头 - 多行字符串以
$符号开头,后面跟字符串长度 - 整数值以
:开头,后面跟整数的字符串形式 - 错误信息以
-符号开头 - 数组以
*开头,后面跟数组长度
单行字符串
+hello john \r\n
多行字符串
$10\r\nhello john\r\n
整数
:1024\r\n
错误
-WRONGTYPE Operation .... \r\n
数组`[1,2,3]
*3\r\n:1\r\n:2\r\n:3\r\n
NULL(使用多行字符串表示,长度为 -1)
$-1\r\n
空字符串(使用多行字符串表示,长度为 0)
$0 \r\n\r\n
两个\r\n之间的内容,就是空字符串。
AOF
Redis 有两种持久化机制——快照和 AOF 日志。AOF 日志是连续的增量备份,它记录的是修改了内存数据的指令文本。在长期运行后 AOF 会变得无比庞大,且数据库重启时恢复需要加载 AOF 日志中的指令进行重放。可以使用bgrewriteaof指令来给 AOF 日志进行瘦身。
Redis 在收到客户端的指令后,会先执行指令才将日志存盘。
COW
COW奶牛,即 Copy on write。掘金上的一篇文章对此有十分详细易懂的讲解:https://juejin.im/post/5bd96bcaf265da396b72f855
COW 技术的实现涉及到了 Linux libc 库中的fork和exec函数。
fork函数用于创建子进程,创建出的子进程,与父进程共享内存空间。也就是说,如果子进程不对内存空间进行写入操作的话,子进程是直接引用父进程的物理空间。
而调用exec函数后,子进程的代码段也会分配单独的物理空间。这时二者就分开了。
因此,开子进程做数据持久化,它与父进程共享同一块物理空间。它并不会修改现有的内存数据结构,而只是对数据结构进行遍历读取。
而当父进程接收到客户端请求,对内存数据结构进行修改时,就会使用操作系统的 COW 机制来进行数据段页面的分离,然后父进程对这个复制的页面进行修改。这时子进程还是原来的那份页面,数据并没有变化。
关于操作系统的 COW 机制:
fork() 之后,kernel 把父进程中所有的内存页的权限都设为 read-only,然后子进程的地址空间指向父进程。当父子进程都只读内存时,相安无事。当其中某个进程写内存时,CPU 硬件检测到内存页是 read-only 的,于是触发页异常中断(page-fault),陷入 kernel 的一个中断例程。中断例程中,kernel 就会把触发的异常的页复制一份,于是父子进程各自持有独立的一份。
正是因为fork()之后内存页权限的只读,才使得后面父进程尝试写内存时引发了异常,从而使得 kernel 复制页。但如果在 fork() 之后,父子进程都还需要继续进行写操作,那么会产生大量的分页错误page-fault(页异常中断),这样就得不偿失了。
管道
Redis 的管道并不是由 Redis 服务器的一项技术,它是由客户端提供的。
比如当需要执行两条指令时,客户端需要先请求指令,再接收消息,再请求指令,再接收消息。两次来回总共有 4 个操作。但如果调整读写顺序,改成“写—写—读—读”,即将两次请求、两次接收都放到一起,那么就只需要一个来回了。
但是这对于服务器来说没有任何区别,仍然还是收到一条消息,执行一条消息,回复一条消息。
可以通过 Redis 自带的压力测试工具redis-benchmark来进行测试。
redis-benchmark -t set -P 2 -q # 设定了两个管道
事务
Redis 的多个连续操作是原子性的,但事务执行不是原子性的。
Redis 的事务使用multi exec discard指令。
multi # 开始事务
incr books
incr books
exec # 执行事务
这里一次只会执行一条指令,因此连续操作是原子性的。但是事务在遇到指令执行失败后,后面的指令还会继续执行。并不会一起成功,一起失败。因此 Redis 的事务其实根本不具备原子性。它只是仅仅满足了事务的“隔离性”中的串行化。
watch
watch 机制是一种乐观锁。它用来解决并发修改时的问题。有一些对于数据的计算修改我们无法让 Redis 在服务器上帮我们计算,因此需要拿到客户端计算完成后再修改 Redis 服务器上的数据。如果在客户端计算时,Redis 上的数据被改动了,我们计算完再提交时就会发生冲突。
这时可以使用watch在事务开始之前盯住一个或多个变量,当事务执行时,Redis 就会检查变量自watch后是否被修改。若被修改了,则会返回NULL通知客户端事务执行失败。
分布式简介
关于 Redis 分布式这部分,因为目前没有这方面的需求,因此我只是看了这部分的内容,但不会在本文中总结了。
CAP 原理
- Consistent 一致性
- Availability 可用性
- Partition tolerance 分区容忍性 当网络分区发生时,一致性和可用性两难全。为了保证一致性,那么就会强行关闭两个不再同步的节点,导致服务不可用。想保证可用性,那么两边节点又不再会进行数据的通信交换,一致性无法再保证。
其实感觉 Redis 分布式这方面,应该是分为两种情况。 一种是主从,通过 Sentinel 来保证主从一致性,主从之间存储的数据是一致的。只是开了好几个节点而已。 另一种是使用 Codis、Cluster 等实现的集群,将数据放在多个 Redis 实例中进行存储,完成海量数据存储与高并发读写操作。
同时在分布式中,特别是像 Redis Cluster 这种去中心化的场景下,我注意到一个十分有意思的现象。比如当一个节点认为某个节点失联了并不代表所有的节点都认为它失联了,集群之间还得进过一次协商的过程——只有大多数节点都认定某个节点失联了,整个集群才认为该节点需要进行主从切换。(Redis 集群可以使用 Gossip 协议来广播自己的状态以及改变对整个集群的认知)
再比如分布式锁,当第一个客户端在主节点申请成功了一把锁,对于客户端而言它是无感知的。当这把锁还没有来得及同步到从节点时,主节点宕机了。这时新产生的主节点内并没有这把锁,那么它就会批准另客户端的加锁申请。这时一把锁同时被两个客户端持有了,问题就产生了。
解决这个问题的 Redlock 算法,其实跟上面的思想很像。加锁时,它会向过半节点发送set指令,只要过半节点 set 成功,就认为加锁成功。释放锁时同理,即向过半的节点发送del指令。
但 Redlock 同时也因为需要更多的 Redis 实例,性能会下降。
淘汰机制
上面将分布式锁时,就用到了 Redis 的expire属性,使得 key 可以到时间过期。但 Redis 是单线程的,因此 key 的过期自动删除操作,其实是在定时遍历轮询中实现的。
Redis 会将设置了过期时间的 key 放在一个独立的字典中,之后定期来遍历这个字典删除过期的 key。同时 Redis 还会使用惰性策略——即当客户端访问这个 key 时,Redis 会去判断 key 是否过期,如果过期了就立即删除。
LRU 算法
当 Redis 内存超出物理内存限制时,它将根据策略淘汰掉一些数据从而腾出新的空间来继续提供读写服务。可以使用maxmemory-policy来配置。
- noeviction 不会继续服务写请求。(但可以使用
del删除) - volatile-lru 淘汰设置了过期时间的 key,最少使用的 key 优先被淘汰。
- volatile-ttl 淘汰设置了过期时间的 key,ttl 最小的 key 优先被淘汰。
- volatile-random 随机选择淘汰设置了过期时间的 key
- allkeys-lru 在全部 key 中,最少使用的 key 优先被淘汰。
- allkeys-random 在全部 key 中随机淘汰。
懒惰删除
还是因为 Redis 是单线程的原因,若使用del指令直接删除一个包含成千上万个元素的 hash,将会导致单线程卡顿。
因此 Redis 4.0 后引入了unlink指令,它能对删除操作做懒处理,丢给后台进程进行异步回收内存。
当执行unlink之后,要删除的数据就已经被分开了,主线程无法再访问到,这时就可以把数据丢到异步线程池里慢慢地删除了。
Redis 安全
其实 CTF 中也有 SSRF 打内网 Redis 然后 getshell 的题目。
这是因为 Redis 默认监听 6379 端口,且默认没有密码,若直接暴露到公网上,那就完了。小则删库,大则 getshell。
可以通过requirepass来设置密码:
requirepass thisismypassword
但如果设置了密码,从节点复制时也就需要输入密码了。可以使用masterauth来设置从节点访问主节点时的密码。
除了外来攻击者,有时我们在维护时,可能也会有一些误操作产生。可以使用rename-command来修改指令的名称,防止误操作。
rename-command keys showmethekeys # keys 会一次性打出所有的 key,从而可能会导致卡顿
若想直接完全封杀某条指令,可以把其别名设置成"",这样就无法使用任何字符串来执行这条指令了:
rename-command flushall ""
因为 Redis 使用 RESP 协议,且不支持 SSL 连接。因此在不同服务器之间转移数据时,可能会存在被中间人窃听的风险。因此可以使用 Redis 官方推荐的 spiped 工具来实现 SSL 安全通信。
总结
综上就是我认为比较重要的一些点,记录下来以备自己日后查找。《Redis 深度历险》这本书还是很棒的!自己花了刚好一个月的时间看完了,看书的速度这么快可能真的是因为很感兴趣吧。但是书后面的源码分析我目前还不太能理解,一是其算法方面的知识太多,二是自己未曾看过太多这种大项目的 C 源码,对于操作系统底层的运作也不是很了解。 但这同时也让我明确了接下来要去学的方向:我想去看看算法以及操作系统的内容。目前都已经找到了合适的书 ,之后就要开始认真看了!果然学自己感兴趣的东西总是能斗志满满呢!

喜欢这篇文章?为什么不打赏一下呢?