
呜哇!你这 kubectl exec 怎么不能指定用户呀?
发生什么事了?
最近在写集群相关的 Side Project,主要是使用 Kubernetes 的 Go SDK 进行开发。其中有个功能需要在 Pod 启动完成后在 Pod 的容器中执行命令。
但在使用 Go SDK 执行命令这里就有一个坑。你会发现在k8sClient.CoreV1().Pod(namespace) 下居然没有形如 Exec() 这样的方法可以使用,GitHub Copilot 也直接在这里傻掉了不知道如何补全。
通过翻阅 kubectl 源码中关于 exec 子命令实现,我找到了这个:src/k8s.io/kubectl/pkg/cmd/exec/exec.go#L353-L366
// TODO: consider abstracting into a client invocation or client helper
req := restClient.Post().
Resource("pods").
Name(pod.Name).
Namespace(pod.Namespace).
SubResource("exec")
req.VersionedParams(&corev1.PodExecOptions{
Container: containerName,
Command: p.Command,
Stdin: p.Stdin,
Stdout: p.Out != nil,
Stderr: p.ErrOut != nil,
TTY: t.Raw,
}, scheme.ParameterCodec)
return p.Executor.Execute("POST", req.URL(), p.Config, p.In, p.Out, p.ErrOut, t.Raw, sizeQueue)
我们可以看到这里其实是直接构造 HTTP 请求对着 Kubernetes APIServer 进行请求,Go SDK 里并没有封装。甚至在上方的注释中还留着一则七年前的“贴心” TODO,说要考虑将这块抽象成一个 SDK 里的方法。转眼间七年过去了,这坑还是没填。😅
需要注意的是 kubectl 的实现最后是用了它自己的 Execute 方法发送了个 POST 请求,但这里其实是需要流式的去读取命令执行所返回的结果。最后应该使用 Stream(),可以参照我的最终代码:
req := e.k8sClient.RESTClient().Post().
Resource("pods").
Name(pod.Name).
Namespace(pod.Namespace).
SubResource("exec")
req.VersionedParams(&coreV1.PodExecOptions{
Stdout: true,
Stderr: true,
Container: containerName,
Command: command,
TTY: true,
}, scheme.ParameterCodec)
// Send the request.
respBody, err := e.k8sClient.RESTClient().Post().AbsPath(req.URL().Path).Stream(ctx)
if err != nil {
return nil, errors.Wrap(err, "post request")
}
defer func() { _ = respBody.Close() }()
然后,我又遇到问题了 —— 有些镜像启动的容器咋 kubectl exec 进去的用户不是 root?同时我也无法使用 su 切换用户。拿着低权用户的 shell 有很多操作都做不了,这该咋办呢?
我便开始在网上搜索 kubectl exec as root,在看了不少官方的 issue 建议和 Stackoverflow 上的奇技淫巧后,我梳理考究了下这个问题的来龙去脉,写下此文来讲述下这个长达六年还未实现的需求背后的故事。
名词辨析
前方预警!在后文中你可能会遇见 containerd、runc、OCI、CRI、Docker 等等这些名词,在正式开始前我们不妨先梳理下这些名词,至少先弄清楚它们之间的关系。
这里先放一张图,各位可以简单瞄一眼后继续往下看。

是造物者之无尽藏也
还记得最开始我在大一上学期的时候接触了 Docker,当时给我印象很深的一句话是:“Docker 这玩意就是新瓶装旧酒。” 所谓容器,只不过是封装了 Linux 系统内核提供的功能去实现资源的隔离。本质还是 Linux Container 的 cgroups、namespaces。
cgroups:用于 CPU、内存、磁盘和网络 IO 物理资源的隔离namespaces:用于 PID、IPC、Network 等系统资源的隔离 以上这些都是 Linux 内核中提供的功能,我们可以看作“是神赐予的”。 我这里想到了苏轼《赤壁赋》里的这句:“是造物者之无尽藏也,而吾与子之所共适。”😋
runc
Docker 开发并使用了一个名为 runc 的程序,用于调用这些神赐予的功能,来创建一个个容器。runc 的功能十分简单,它本身是一个命令行程序,也就只能用来做创建容器(runc create)、开启容器(runc start)、列出容器(runc list)、删除容器(runc delete)这些基础功能。
runc 背后的原理是使用 C 语言编写的代码调用系统的 namespaces 和 cgroups 来创建容器,然后在 Go 层面使用 CGO 调用 C 语言,封装成了 libcontainer 这么一个库。
runc 遵循 OCI(Open Container Initiative)规范中的 Runtime-Spec。这个 OCI 是 Docker 当年牵头制定的,分为 Runtime-Spec 和 Image-Spec,分别制定了运行时和镜像的规范。
我们将 runc 这种只能启停容器的十分底层的容器运行时叫做低级容器运行时(Low-Level Container Runtime)。这么称呼是为了和后面提到的 containerd 这种**高级容器运行时(High-Level Container Runtime)**区分开来。
containerd
那 containerd 又是啥呢?containerd 基于 runc 的实现了启停管理容器的能力,同时自身还支持了对容器镜像的管理,就如我们用的 docker pull docker push 推拉镜像,导出镜像等功能。它这里关于镜像的功能也是遵循着上面提到的 OCI Image-Spec 的规范。
而跟我们日常打交道的 Docker,准确的说是 Docker Engine,其又是在 containerd 上简单套了层壳,我们的拉取镜像、启停容器,其实最后还是落到了 containerd 身上去执行。像 containerd 这样的高级运行时还有 CRI-O。
震惊!
好的,如果到这里你还没晕的话,那我们可以插个题外话来讲讲前年 Kubernetes 那条被国内公众号疯狂标题党的新闻了:
前年 Kubernetes 官方宣布将在未来发布的版本中弃用 dockershim,直接在源码中删掉 dockershim 的部分。官方的解释可以看这篇文章。
这事传到国内公众号就变成:“Kubernetes 宣布不再支持 Docker 运行时” 这种标题党文章。我们上面聊到了 Docker Engine -> containerd -> runc 这层关系,而 dockershim 则是用于处理 Kubernetes -> Docker Engine 这层关系的。
由于当年 Docker 刚出来一家独大,野蛮生长的过程中做了很多不是那么规范的事情,Kubernetes 之后才制定了容器运行时接口 CRI(Container Runtime Interface) 规范(注意跟上面那个 OCI 是两个东西)来约束容器运行时的行为。但 Docker 这东西毕竟先出来并不遵守 CRI,它出来混的时候还没你 CRI 甚至 Kubernetes 什么事呢!
后面 Kubernetes 想遵守 CRI 规范整合接入各种运行时的时候,就不得不为 Docker Engine 当年的所作所为“买单”,也就是写了 dockershim 这么个东西作为中间层让 Docker Engine 遵循 CRI 规范进行接入。dockershim 这坨“屎山”越来越繁重,后面 Kubernetes 直接开摆不想干了,直接把 Docker Engine 去掉吧,我们直接拥抱遵守 CRI 规范的 containerd!
整个关系也就从:
Kubernetes -> Docker Engine -> containerd -> runc
变成了
Kubernetes -> containerd -> runc
确实也没什么问题,你 Docker Engine 不也是 containerd 套壳嘛,这也就是为什么我们现在 docker build 的镜像仍可以在 Kubernetes 正常使用的原因,因为这些都是遵守 OCI Image-Spec 的。唯一的不同只不过是你切到集群节点上,用 docker ps 看不到容器了,而是要用 containerd 的 CLI 命令 ctr --namespace k8s.io containers ls 去查看容器。
问题出在谁身上呢?
理清了上面这些概念后,我们就可以来调查究竟是谁的问题了。还记得我们的问题是什么吗?kubectl exec 怎么不支持指定用户(比如 root)执行命令?
首先,看最终的低层容器运行时 runc 的源码:opencontainers/runc exec.go#L48-L51,命令行参数里居然是支持指定 UID 和 GID 的!该参数后面会被传入到 libcontainer,在 cgroups 中 opencontainers/runc libcontainer/specconv/spec_linux.go#L456-L462 最后使用 os.Chown 赋予指定用户操作的权限。
那再往上追到 containerd,找到 containerd 中 ctr task exec 的源码部分,发现使用了 OCI 规范中定义的结构体 Process,该结构体定义了在容器中启动进程需要的信息,其中就有 User 字段用于指定用户!
那…… 既然 OCI 规范里都支持了,再往上追就只有一个了:Kubernetes 定义的 CRI 规范。在 kubernetes/cri-api 中我们找到了 CRI 规范的 Protobuf 定义文件,其中的 ExecRequest 确实不支持指定用户……
同时我还发现有个老哥试图提 PR #59092 让 CRI 规范支持这个功能,他也是在 Proto 文件里加了这么一个字段。在下面的评论中我们也发现这居然是 Kubernetes TOP3 的期望功能。可惜这个 PR 后面不明不白地就被关了。
在 containerd 中我也看到了有人提出了这个问题 #6662,containerd 的人也表示很无奈,想让 kubectl exec 支持指定用户,那就只能让上层改 CRI 规范,然后它们下层做适配,但是这事现在一直被搁置着,也没个人来推。
一直…… 搁置了六年。
代码还是得写的,该如何解决呢?
日子总是要过的,代码还是得写的,真的就没有办法了吗?
其实不然,在 issue #30656 里有人提出了一种很蠢的办法:
安装一个 kubectl 插件,使用 kubectl ssh 连上对应的节点宿主机,然后找到容器直接执行命令。这真的真的是太蠢了。
我在这个 issue 下找到了这么一个项目 ssup2/kpexec,借鉴其中用到的方法相对优雅的解决了这个问题!这里放一下 kpexec 项目的架构图用于方便说明:
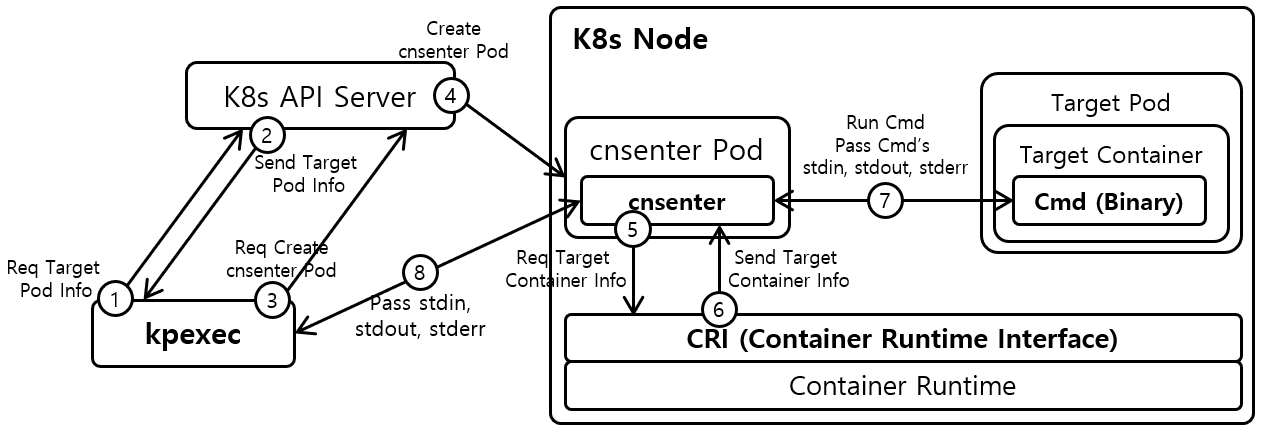
我的做法其实比它更简单。我们上面提到了,容器系统资源隔离本质上还是使用了内核中的 namespaces,所有的虚拟化都是在操作系统层面完成的。 而系统中有 nsenter 这个命令,可以帮助我们进入到对应容器的 namespace 命名空间中,在该命名空间中执行命令,默认的用户权限就是 root!
假如我们要在部署于 A 节点的 Pod 的容器 B 下以 root 权限执行命令,步骤如下:
- 在 A 节点下创建一个特权容器,即获得了宿主机节点的操作权限。使用 nsenter 进入 PID = 1 的命名空间执行命令,也就相当于直接在宿主机上执行命令。
- 在宿主机上调用 crictl inspect 命令查看容器 B 的 PID。
- 再次在宿主机上使用 nsenter 进入容器 B 的命名空间,以 root 用户执行命令。
我的最终代码如下:
// Get the container CRI information by execute the `crictl` command in node, then execute as root with `nsenter`.
execCommand := []string{
"sh", "-c",
"nsenter -t 1 -m -u -n -i crictl inspect " + hostContainerName +
" | jq -r .info.pid | xargs -I {} nsenter -t {} -m -u -n -i sh -c '" + strings.Join(command, " ") + "' || true",
}
满足 CRI 规范的高级运行时均可以使用 crictl 来进行操作。这样我们就不用再傻傻去判断 Docker Engine、containerd、CRI-O 然后再傻傻调各自的 CLI 了。这里使用 crictl inspect 加容器名称查看容器信息,使用 jq 提取出返回 JSON 中记录的容器 PID。最后特权容器进入该进程 PID 所在的 namespace 执行命令。最后还加个 || true 来确保最后执行的命令一定是正常退出的。
(不要在这里跟我 ky 什么命令注入漏洞啥的,command 是从可信的来源传入的,前面已经做了权限检查)
至于一些细节,比如用 NodeSelector 去将特权容器部署到与执行命令相同的 Node 上,怎么获取 pod.Status.ContainerStatuses 中的 HostContainerName 这些,就不再赘述了。大家自己动手写写就都知道了。
最后说几句
可能本文前面的篇幅有点长了,最后的 nsenter 反而没有过多着墨。不过确实梳理过这些名词后,我对于以 Docker 为起点的容器这套东西的理解更加透彻了些。
今天也抽时间看了些 Kubernetes 攻防相关的资料,感觉容器逃逸像 runc CVE-2019-5736 这个洞,本质上还是相关的运行时软件在操作不可信的容器环境时,行为上过于“侵入”或者“依赖”容器内的不可信环境从而出了问题。runc 这个是把自己传到了危险重重的容器里,以前的 CVE-2019-14271 docker cp 容器逃逸,是因为使用了容器内的 so 库。容器内的进程本质上只是一个受限的普通 Linux 进程,其对宿主机是完全透明的,我感觉这也使得它与宿主机的界限变得模糊,有种很容易就能被突破的感觉。
大概是一年前,我对 Kubernetes 还是持有一种较为厌恶的情绪的,啥也不懂的我也学着大家当乐子人玩 YAML 工程师的梗。今年三月的 D^3CTF,我用 Kubernetes Go SDK 写了个动态开启靶机的程序。在那之后我对它的印象有了很大的改观。不愧是生产级别的容器调度程序,我想删掉一个 Pod,它就是能给我删掉,不像 Docker 有时候 --force 强制了但是 Docker Engine 会迷之卡顿然后没删掉。Kubernetes 能给我带来一种安心的感觉。
推荐阅读:
- Docker、Containerd、RunC分别是什么:名词辨析比我上面写的更加详细。
- containerd-containerd-shim和runc的依存关系:从源码层面分析了三者的依存关系,很有意思。
- 从零开始的Kubernetes攻防:除了容器,基于容器的 Serverless 服务也是我很感兴趣的一个方向,我从这里学到很多有趣的攻击方法。

喜欢这篇文章?为什么不打赏一下呢?