
Python 开发自己的语音助手初探
入门先别玩蛇
呼~ 英语四级考完了。接下来应该就是坚持每天抽时间看一下线代,争取期末能过什么的了。
这几天一直在看 Python。一直以来对于这个语言的印象都不是太好,觉得它的语法太怪异了。(想了起游标卡尺的梗2333)但是现实所迫,很多时候用 Python 写脚本可以完成很多费劲的琐事。CTF 中也有很多要用 Python 写脚本的时候。同时我也不满足只会 PHP 这一门后端语言……
嘛,放平心态后,我开始学这门语言了。
半个月下来,我觉得 Python 这个嘛……真的不适合刚入门编程的新手学,我承认它确实能很快很简单的做出很多很酷的东西。但是它同时也省略了太多。
我认为编程时学的第一门语言至关重要,它会为你塑造了你心中对于编程最初的印象,同时会使你养成很多你自己察觉不到的习惯。就比如我最开始是从 ActionScript3 入门的。很幸运,它的语法和 JavaScript 超级相似,因为都是 ECMAScript 标准的。同时 AS3 是一门面向对象语言,这又和 Java 挺像的。
但是 Python 这个嘛…… 定义变量不用加关键词,句末不用写分号,语句块全靠缩进;面向对象确实是有,但是 Python 的类中并没有真正 private 的属性,你依然可以使用一个很奇怪的变量名来访问它。
所以,我觉得刚入门真的不适合玩 Python 这条蛇。这条蛇玩舒服了,你想去玩大象PHP,玩地鼠Go,直接一脸懵逼,开始疯狂骂这些语言设计的多么麻烦,然后陷入一口一个“人生苦短,我用 Python” 无脑吹 Python 的循环中。
为了伯伦希尔的荣耀
单纯看书是没什么意思的,边看书边写点小玩意,踩点坑才有意思。
初二的时候刚开始学 AS3 时,写了个还算不错的语音助手。用的是百度的 TTS 和语音识别接口,以及图灵机器人的对话接口。唯一不足的是,图灵机器人可定制化的东西太少,都是些已经设定好的对话问答,搞不了什么个性化东西。
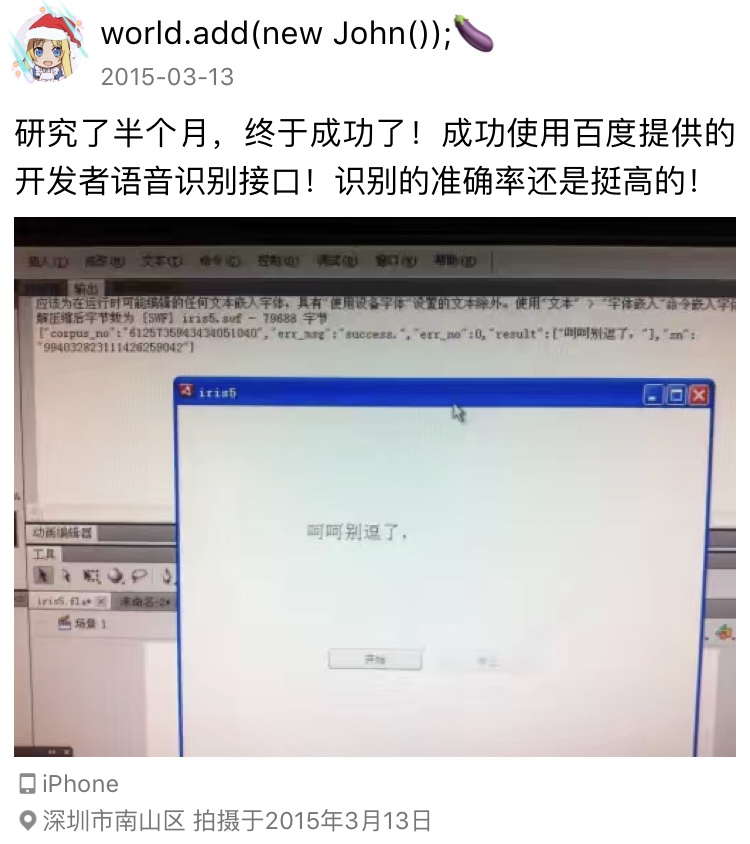 这个程序也随着之后 Flash 被淘汰了而不了了之了。但确实让当时中二的我十分满足。
高三的时候又心血来潮想写这么个东西了。当时是因为偶然了解到了 Google DialogFlow,这是一个可以自己定制做出一个聊天机器人的东西。只需要创建好意图,把语料放进去,然后就可以了。同时提供 Slack 等一系列平台的接口。
这个程序也随着之后 Flash 被淘汰了而不了了之了。但确实让当时中二的我十分满足。
高三的时候又心血来潮想写这么个东西了。当时是因为偶然了解到了 Google DialogFlow,这是一个可以自己定制做出一个聊天机器人的东西。只需要创建好意图,把语料放进去,然后就可以了。同时提供 Slack 等一系列平台的接口。
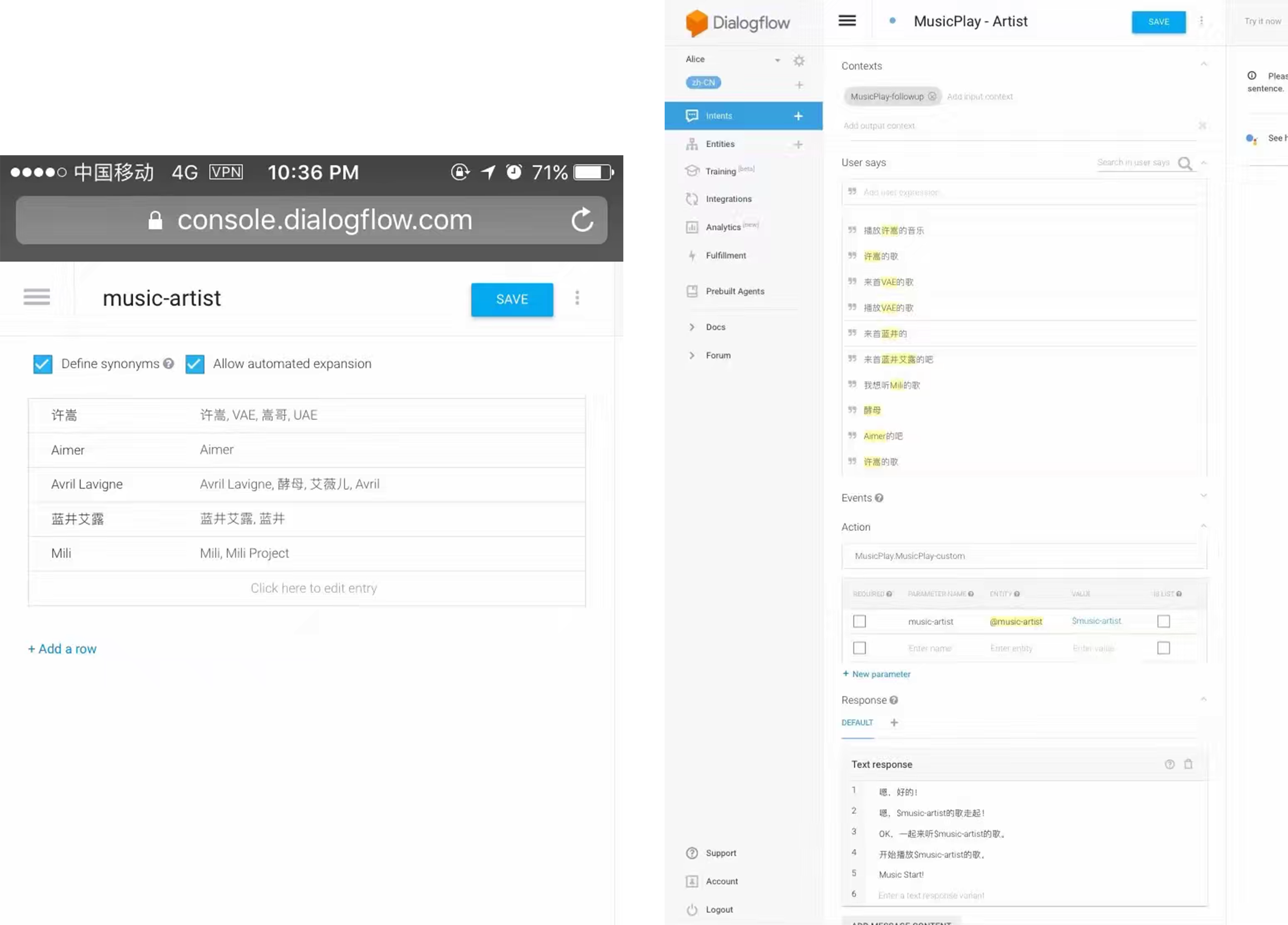 百度现在在搞的
百度现在在搞的理解与交互技术UNIT,我之前试了下,和 DialogFlow 几乎是一样的,说白了其实就是百度抄过来的。
只是当时高三忙于学业,可能吧本来想用 PHP 写的,最后也是不了了之了。
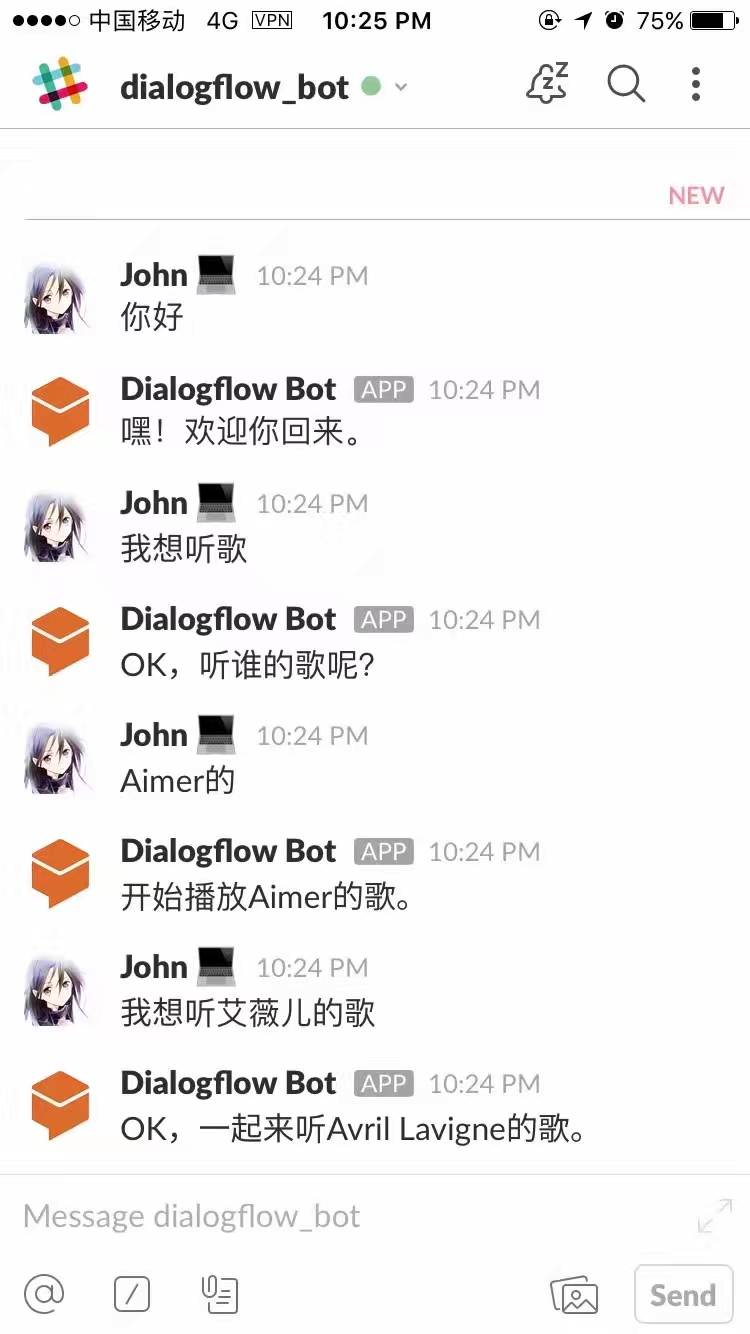
我们再来一遍
那么这次就用 Python 再来一次吧。
图形化界面 PyQt5
我是想做成一个图形化界面的软件,然后放到树莓派上跑。之前在大佬室友那里了解到了 Qt,看到它可以直接拖控件画界面,便选择了这个。 首先先是我的第一个误区——**Qt 这个不是一个 UI 框架!**它是包含一整套功能的类库,最初是用在 C++ 开发上面的。我在推特上看到 mian 学长在写 C++ 时经常会用到。 在 Python 上使用的叫做 PyQt,GUI 只是它的一个小功能而已。将它引入项目时是这样的:
from PyQt5 import QtCore, QtGui, QtWidgets
其中 QtGui、QtWidgets 就是我们想要用来搭界面东西了。
在 PC 上,我们会使用 Qt Designer 这个软件来画界面,保存下来的是.ui文件,之后再转成.py文件放入项目中。
而在 Mac 上面并没有 Qt Designer 这个软件。它被集成到了 Qt Creator 里面。因此我需要在官网下载安装这个 app。进入后不要创建项目,仅单独创建 Qt Design Form,因为创建的项目都是给写 C++ 的用的。
包管理器 pip
下一个坑,是我们需要安装 PyQt5,pip3 是 python3 的包管理器。 安装其实很简单:
sudo pip3 install PyQt5
但是,这里我又踩了个坑。我是使用学生优惠白嫖的 PyCharm 进行开发的,创建项目时有个指定项目环境的,我选择的是Virtualenv,也就是venv。
这就是一个虚拟的 Python 环境,创建后界面下方就有一个控制台,在这里面用 pip 安装的包,不会对系统的 Python 环境产生影响。因此我们应该在这里面安装 PyQt5。(愚蠢的我直接开系统控制台搞,差点没玩脱)
给控件绑定方法
这是我搞图形界面开发时最喜欢的步骤,不管是 iOS 开发,Visual C# 开发都是。我超级享受把界面上的按钮与代码中的函数“绑”在一起的过程。 在 PyQt 中这十分简单。 给按钮绑上点击后的事件:
self.myBTN.clicked.connect(self.buttonClick)
这使得我们点击myBTN按钮后,会执行buttonClick函数。短短的一行,很舒服。
同时,给控件指定属性也很简单:
self.showLabel.setText("")
这样就设置了showLabelLabel 的值,输入框也可以这样使用。具体的更多玩法可以去看 PyQt5 的文档(前提是能找得到,它的文档太杂了)
调用百度 TTS 接口
我之所以用百度的接口,是因为我之前收到过百度的邮件,宣布它们的人工智能开放平台上的接口,个人用户免费用!大部分的接口 QPS 都是 10,即一秒最多请求 10 次。对于个人用的项目,这个限制条件完全跟没有一样啊!
百度的 TTS 接口可以通过 Restful API 调用,这就是我当年用 AS3 进行开发时使用的方法,所有东西都是 HTTP 请求指定的接口。但是对于 Python 等主流语言,百度提供了 SDK,直接下载下来import进入项目即可(不想下载压缩包还可以用 pip 安装)
from aip import AipSpeech
""" 你的 APPID AK SK """
APP_ID = '你的 App ID'
API_KEY = '你的 Api Key'
SECRET_KEY = '你的 Secret Key'
client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
result = client.synthesis('你好百度', 'zh', 1, {
'vol': 5,
})
# 识别正确返回语音二进制 错误则返回dict 参照下面错误码
if not isinstance(result, dict):
with open('auido.mp3', 'wb') as f:
f.write(result)
这是百度官方文档里的示例代码,它会向服务器发送请求合成你好百度音频后保存到本地。**注意这里有一个天坑!!**写文档的程序员应该是手误,把audio.mp3错写成auido.mp3,导致我之后用 PyGame 播放音频总是报错找不到文件。真的坑!
不过总的来说,体验还是很舒服的,短短几行代码就实现了语音合成,也是彰显了 Python 的牛逼吧。“我也不知道这内部什么合成原理,反正import就好了。”
播放音频
使用 Python 播放声音时,很多人都会使用 Pygame 这个框架。这原本是用来做游戏的,仅仅拿来播放声音好像有点大材小用了哈。
import pygame
# 播放声音
pygame.init()
pygame.mixer.music.load("audio.mp3")
pygame.mixer.music.play(0) #0 表示只播放一次
但是,这里一直有个问题我到现在都没解决。因为 mp3 是一种闭源的格式,所以我感觉 PyGame 好像不能很好的处理它,播放出来的声音都是升了一个调的,音调十分奇怪。在网上也找不到合适的解决办法,同时也找不到用来替代的其它播放声音的库。如果有大佬知道怎么解决,请告诉我,感激不尽。
语音识别
语音合成也是百度 API 一把梭。
# 识别本地文件
recordResult = client.asr(get_file_content('rec.wav'), 'wav', 16000, {
'dev_pid': 1536,
})
try:
recordResult = json.loads(json.dumps(recordResult))['result'][0]
except KeyError:
print("No result, error!")
else:
self.textEdit.setText()
say(recordResult)
这里我现学现卖了一下,使用了异常处理。因为如果传上去的音频没说话,或者音质不清晰,传回的 JSON 中会报错,同时也没有result这个键。所以我们只要捕获KeyError这个异常就行,如果抛出了异常,就说明未识别成功,然后报错。
书上讲异常处理这一章时提到的一句话我很欣赏——“请求宽恕易于请求许可”。这话十分耐人寻味啊,大概就是:与其事先想好会遇到的所有问题,不如直接放手去做,遇到了问题再说。(看个 Python 还给我看出人生哲理来了23333)
当检测到停止说话时才停止录音
这是一个难点,说是还要用什么鬼的傅里叶变换,一脸懵逼。 周五的线代课上我在 Stack Overflow 上寻找着这个问题的答案。最后还是给我找到了。其实难点就在于我们怎样实时获取当前说话的音量。
# 计算当前音频声音
swidth = 2
SHORT_NORMALIZE = (1.0/32768.0)
def rms(frame):
count = len(frame) / swidth
format = "%dh" % (count)
shorts = struct.unpack(format, frame)
sum_squares = 0.0
for sample in shorts:
n = sample * SHORT_NORMALIZE
sum_squares += n * n
rms = math.pow(sum_squares / count, 0.5)
return rms * 1000
其实我也没太看懂这是什么个原理,直接 command c + command v 就过来了。面向 Stack Overflow 编程 之后就是录音的主函数:
def rec(file_name):
CHUNK = 1024
FORMAT = pyaudio.paInt16
CHANNELS = 2
RATE = 16000
MAX_RECORD_SECONDS = 8
TIMEOUT_LENGTH = 2 # 音量小于一定时间后停止录音
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=1,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("开始录音...")
frames = []
endTime = time.time() + MAX_RECORD_SECONDS # 超过此时间自动停止
lastTime = time.time()
while True:
if lastTime < endTime:
input = stream.read(CHUNK)
frames.append(input)
# 声音大小,小于音量后超过多少秒停止 / 超过多长时间停止
rms_val = rms(input) # 当前音量
if rms_val > 1: # 如果说话了(音量大于 1)就更新时间
lastTime = time.time()
if time.time() - lastTime > TIMEOUT_LENGTH: # 超过一定时间不说话,停止录音
break;
else: # 超时停止
break
print("录音结束")
stream.stop_stream()
stream.close()
p.terminate()
wf = wave.open(file_name, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
wf.close()
print("保存文件成功")
中间那一段判断录音结束是我自己写的哦<(▰˘◡˘▰)> 快夸我快夸我!
大概解释一下好了,这里有一个MAX_RECORD_SECONDS变量,用来记录最长录音时间,录音超过这个时间不管有没有说完都停止,还有个TIMEOUT_LENGTH是在检测到音量小于 1 后多少秒停止录音,(即当做说完话处理)因为我们在正常说话时,音量也是会有小于 1 的时候。
首先先是记录一下停止的时间,超过这个时间必须停止:
endTime = time.time() + MAX_RECORD_SECONDS # 超过此时间自动停止
然后记录当前的时间,并进入循环开始读取音频流,同时用那个判断音量的函数实时计算说话音量。
如果当前说话音量大于 1,就把当前时间赋值给lashTime,这个lastTime就是用来记录说话结束的时间的。如果说话声音小于 1,那它就不变了。
if rms_val > 1: # 如果说话了(音量大于 1)就更新时间
lastTime = time.time()
之后就是比较lashTime和现在的时间差是不是超过了TIMEOUT_LENGTH。超过了就说明已经停止说话好一会了,这时就break跳出循环停止录音
if time.time() - lastTime > TIMEOUT_LENGTH: # 超过一定时间不说话,停止录音
break;
最后那个else是用来判断是否超时的,超过了录音时长同样也跳出循环停止录音。
嘛,还是有点成就感的哈。
就是这些
以上这些完成后一个语音助手的难点就解决了,至于语义分析并给出回复我打算用 PHP 调 Google DialogFlow 在后端完成。Python 这部分只要 GET 请求就好。 还没把程序放到树莓派上去跑,其实只需要在树莓派上搭好一样的环境就可以了。之前只测了下 PyQt 的图形化界面,完全兼容! 嗯,大概就是这些东西了。今天中午把 Python 的书拿去图书馆续借了,还有不少没看完的。看完这本书后我就可以开始学 Python 后端开发啦!想想都开心!搞不好那就是寒假的事了哈哈。 最后附上两年前的一个 flag:
唔~还是要继续加油啊!

喜欢这篇文章?为什么不打赏一下呢?