
我只是想要一个简单轻量的 K8s 镜像预热而已!
最近一个多月,我的生活发生了很大的变动。2 月 15 日因为一直以来积攒的情绪,心情很差。那天深夜我提了离职,离开了从零开始一直干了两年多的公司。
后面又是因为一些不方便明说的原因,经营了两年多的 NekoBox 被迫关站。之后我会针对这个事情专门写一篇文章,说明背后到底发生了什么,以及分享这两年来的心得体会,同时给之前老用户提供数据存档取回的渠道。整件事情发生的挺突然的,对我而言也算是一种人生体验吧,哈哈。
今天想要分享的,是 Cardinal Pro 平台在今年 HGAME 2023 比赛时遇到的一个问题,以及我给出的解决方案,可能不是很完善,还请各位多多指点。
诶?我新加的节点怎么不能用?!
今年的 HGAME 2023 是协会第一次使用我开发的 Cardinal Pro 平台举办,相比之前使用 PHP 开发的平台,最大的特色就是平台支持基于 Kubernetes 动态启停选手独享靶机,相比之前由出题人单独使用各自的学生机部署共享题目环境,有了质的飞跃。
这里插播一条广告,如果你有相关比赛 / 培训需求,想使用 Cardinal Pro 商业竞赛平台,欢迎联系杭州凌武科技~
跟往年的协会寒假招新赛一样,HGAME 2023 是一个长达一个月的比赛,细分为四周单独计算排名,对应到比赛平台里就是四场比赛。参赛人数也是逐周递减,能坚持到最后的新生,才有可能挺进最后的总决赛。所以对于平台而言,我们要应对的就是比赛刚开始时第一周的突发流量以及选手动态靶机开启需求。
在第一周的时候,运维的同学查看集群状态发现集群内 Pod 数量较多,节点相对压力较大,因此新加了一个节点进集群。相对应的,后面开启的题目靶机也就会被 K8s 优先调度到新开的空闲节点上。然后问题就出现了 —— 平台上选手题目环境一直开不起来,最后超过设置的超时时间,前端返回报错。 经过排查发现,是因为本次比赛为了尽可能的节约成本,集群大多使用边缘节点,有一些节点的网络环境可能偶尔抽风,导致无法连接上镜像源拉取镜像。当时临时的解决方案是重新换了其他网络正常的边缘节点拉取。
后来讨论了下,认为集群内需要有个镜像预热的功能,提前将需要用到的镜像拉取到本地。因为流量高峰就是在比赛初期,这时往往也是第一次拉取镜像,一炸就会炸一片很影响用户体验。
现有的轮子太重了
搜索了下相关的资料,发现阿里开源的 Dragonfly 和 Openkruise 项目都支持镜像预热的功能。
Dragonfly
Dragonfly 是作为一个 P2P 文件分发系统被设计出来,最初的目的是为了支撑双十一背后的服务器间大规模的文件分发需求。而容器镜像本质上也是存在磁盘上的一层层文件,所以也就顺带支持了。具体的介绍文章可以看这篇:《直击阿里双11神秘技术:PB级大规模文件分发系统“蜻蜓”》。
但是当我正准备选择搭建 Dragonfly 时,我发现这东西搭起来咋还需要 Redis 和 MySQL???以及它对于 Docker 运行时的镜像分发,还需要我编辑 /etc/docker/daemon.json 文件添加私有的镜像源并重启 Docker 运行时。
这种侵入式太强的配置我并不喜欢,因此放弃了使用 Dragonfly。
Openkruise
我在我自己的集群里使用了 Openkruise 来给 Elaina 代码运行器做容器预热,相比 Dragonfly 的自己启动了一个 HTTP 代理作为私有镜像源,Openkruise 则是定义了一个名为 ImagePullJob 的 CRD (Custom Resource Define) 定制资源用于描述镜像预热的策略。我可以指定拉取镜像的名称以及拉取策略,Openkruise 默认会在每天零点检查一遍是否有镜像没有拉取。
在部署上,也只是一个 Controller Pod,然后在每个节点上 DaemonSet 都起一个 Daemon Pod,相对来说比较轻量。
但是就比赛平台来说,每次出题人上传了一道题目,就要手动创建一个 ImagePullJob 资源来配置这个题目的镜像预热。这个工作交给运维的同学手动来做不太合适,直接耦合进平台让它去参与管理 Openkruise 的资源也不优雅。
况且 Openkruise 仅仅只是自动从镜像源拉取镜像罢了,遇到上文提到的节点本身网络有问题,连不上镜像仓库,还是无解。
集装箱叉车启动!
综上,我想要的仅仅只是一个简单轻量,能在集群节点间同步指定命名空间内 Pod 镜像的组件。所以就有了 forklift 这么一个项目:https://github.com/wuhan005/forklift ,forklift 的中文翻译是叉车,也就是港口码头用来搬运集装箱的那玩意,用在这里还挺贴切的。
先放一张我粗略画得架构图,然后我再来详细分享下它的一些实现细节:
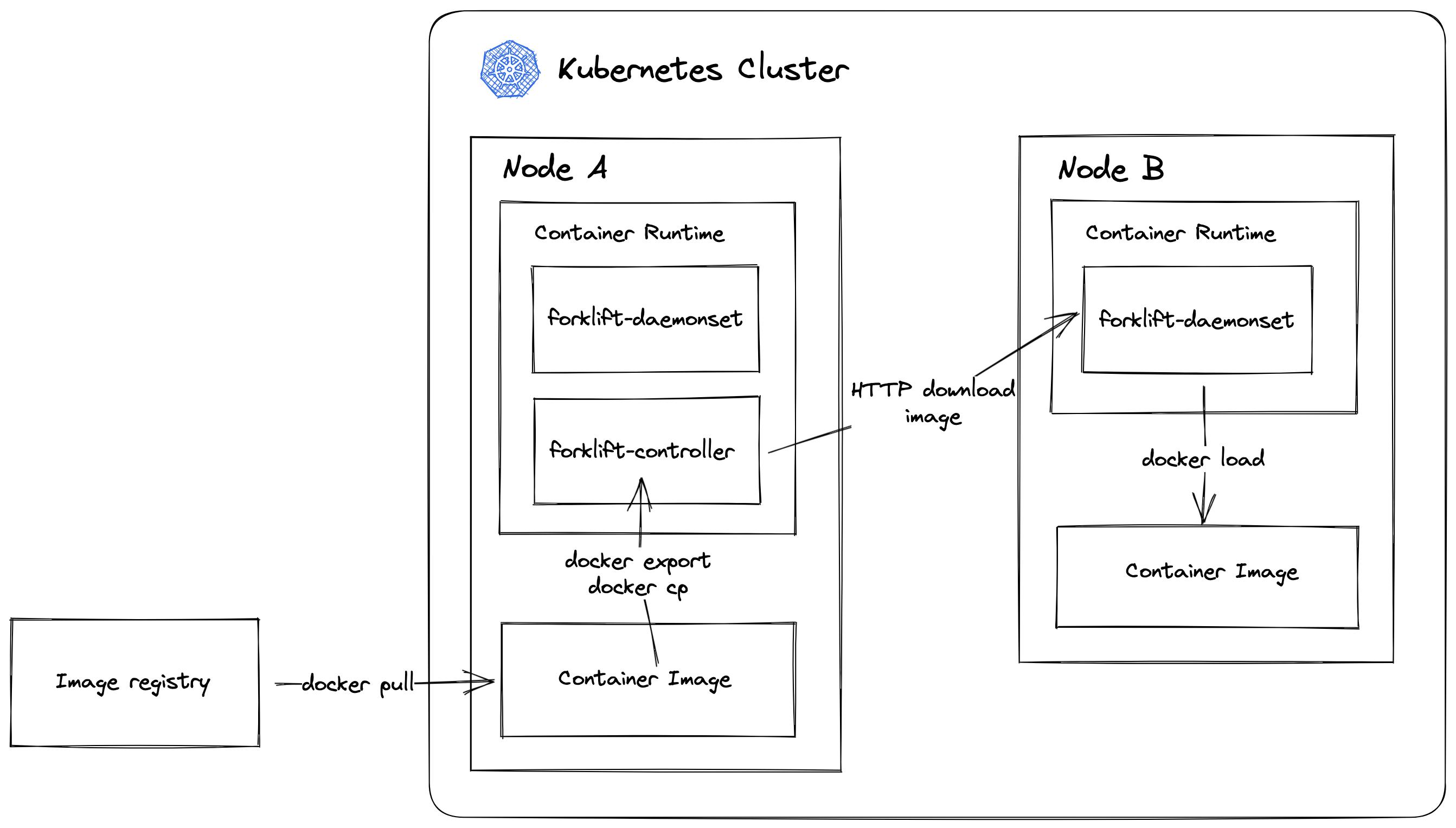
同 Openkruise 一样,我会在集群里的一台节点上部署一个 forklift-controller 作为主的控制器,这台节点也就担任起了从外部拉取镜像并分发的工作。实际在生产中我们可以用 Node Selector 来指定一台网络好磁盘大的节点作为 Controller。
所有的节点上都会部署一个 forklift-daemonset 用于定时轮询 controller,与自己本地已有的镜像做对比,看是否有缺失的镜像需要拉取。如果需要拉取则去请求 controller。
不论是 forklift-controller 还是 forklift-daemonset,它们为了能操作自身节点宿主机上的容器运行时,因此都是部署为特权容器,并且能访问到宿主机的进程。具体的宿主机命令执行方式可以阅读我之前的文章:《呜哇!你这 kubectl exec 怎么不能指定用户呀?》
同时还要挂在一个带集群 Pods 列出查看权限的 ServiceAccount Token 到 Pod 内,因为需要获取指定命名空间下的 Pod 镜像信息。
forklift-controller
对于 Controller 而言,用户通过在 ConfigMap 中指定需要同步镜像的命名空间,ConfigMap 以配置文件的形式被挂载到容器中。Controller 读取配置后,启动一个简单的 HTTP 服务,根路由 / 返回指定命名空间下的所有 Pods 镜像。
/load 路由根据传入的镜像名,返回镜像文件包。如果 Controller 节点上事先不含这个镜像,那么它会操作宿主机执行 docker pull 命令去拉取;之后再 docker export 到宿主机,导出后宿主机执行 docker cp 复制镜像的 Tar 包到 Pod 的容器内,最后在 HTTP 响应中返回。
这里有一个比较蛋疼的点:我在执行 docker cp 命令时,完整的命令如:docker cp /tmp/image.tar <containerID>:/tmp,其中的 <containerID>,也就是容器 ID,应该如何正确的获取呢?
在网上找了一圈,得到的办法也只有一条条遍历筛选当前 Pod 的 ContainerStatuses,找到 Name 为当前容器名的 Status 记录,再读取这条记录中的 ContianerID 字段,真的是有够暴力的。
那么我又怎么得知当前 forklift-controller Pod 在集群内的名字呢?答案是通过读取 HOSTNAME 主机名环境变量!
这些方法不知为何总给人一种不是那么可靠的感觉….. 如果你有更好的办法,欢迎指出。
forklift-daemonset
Daemonset 则会每五分钟请求一次 forklift-controller 的 HTTP 服务,获取需要拉取的镜像列表,同时与自己节点上的镜像进行对比。发现有自身不存在的镜像,则去请求 /load 接口下载获取。整个过程与 Controller 刚好是相反的,Daemonset 下载完镜像到 Pod 容器后,操作宿主机执行类似 docker cp <containerID> /tmp/image.tar 的命令复制下载后的镜像 Tar 包到宿主机,之后执行 docker load 导入。
这样的 docker export 和 docker load 镜像导出再导入的办法,可以保证镜像的名称绝对不会有问题。不像 Dragonfly 从自己启动的代理镜像源拉取镜像,拉取的镜像名称前面的 Host 会是代理镜像源 URL 中的。
目前 forklift 仅支持 Docker 这一个 CRI,我留了一个 Interface,用于实现之后的 containerd 等其它运行时,其实也就把其它运行时的镜像列表、拉取、导入导出给实现就行了,本质上还是去宿主机上执行命令调各种 CLI。
type CRI interface {
ListImages(ctx context.Context) ([]*Image, error)
PullImage(ctx context.Context, image string) error
LoadImage(ctx context.Context, image, sourcePath string) error
ExportImage(ctx context.Context, image, destPath string) error
}
我该怎么愉快的开发调试?
以上就是 forklift 的大致原理,听起来确实很简单易懂,但是我在本地开发的时候却疯狂抓耳挠腮。不在集群环境里开发集群组件,“如何在本地方便的调试?”成了我的一个大难题。 我咨询了下在上海某司做开源 K8s CI/CD 产品的同学,他说他们调试就是代码写完后跑自动化 CI 打包 Dockerfile 部署到集群里看。所以在那之前也会有意识地在代码里多输出日志,因为部署一次的时间周期挺长,最好争取一次搞定。这种行为在我听来十分的荒唐,我想我大概知道他们活干得慢人手不够的原因了……
偶然的一次,我刷到了一篇公众号文章 《为什么在 Kubernetes 中调试应用的体验如此糟糕?》 ,文中介绍了 Telepresence 这么一个项目。它以部署 Sidecar 的形式,拦截集群中发送至指定 Pod 的流量到本地,同时使得本地可以直通集群内部的网络。并且为了避免对线上生产环境造成影响,它还支持设置带上指定的 HTTP Header 后才触发流量拦截。因此我只需要本地 GoLand 编译代码运行即可。forklift 需要连接线上 K8s API,开启 Telepresence 的话直接使用 https://kubernetes.default/ 就能访问,同时 Controller HTTP 服务的 Service,也可以直接在本地进行访问。
Telepresence 算是帮我解决了网络上的大难题,至于 ServiceAccount Token 的挂载,就只能在代码里将其写成可配置的,读当前运行路径下的文件了。文件挂载上目前倒确实没有啥更好的办法。(悲
让 ChatGPT 帮我写 Helm Chart
代码写完跑通后,后面就该想想怎么样让用户方便的部署了。我自己的集群一直是在用 ArgoCD 以 Helm Chart 的形式部署各种应用,这次也打算自己试试打包一个自己的 Chart。
网上搜索关于 Chart 开发的入门教程,往往都是让你执行如 helm create forklift 这样的命令,创建一个已经包含了 Deployment,Ingress,Service,甚至 HPA 的基础 Chart。这一堆 YAML 再配合上 Go 那反人类的模板语言,直接给人看懵了,完全无从下手。😥
并且它还会给贴心地给你展示一些“高级用法”,比如有个 _helpers.tpl 文件可以定义共用的模块,有个 tests 文件夹给你写个类似于测试一样的东西。但我只是想封个简简单单的 Helm Chart,自己再指定几个参数允许用户自定义而已啊!!!
突然,我想到自己在线上集群测试的时候,曾写了几个 YAML 来部署需要用到的各种资源。再加上这段时间写代码没少麻烦 ChatGPT,我就在想能不能让 ChatGPT 帮我基于现有的 YAML,给我生成出 Helm Chat 来。试了下效果还真不错。我们只需要将之前的几个 YAML 全部合并到一个文件中,然后一起喂给 ChatGPT 让它帮忙生成就行。
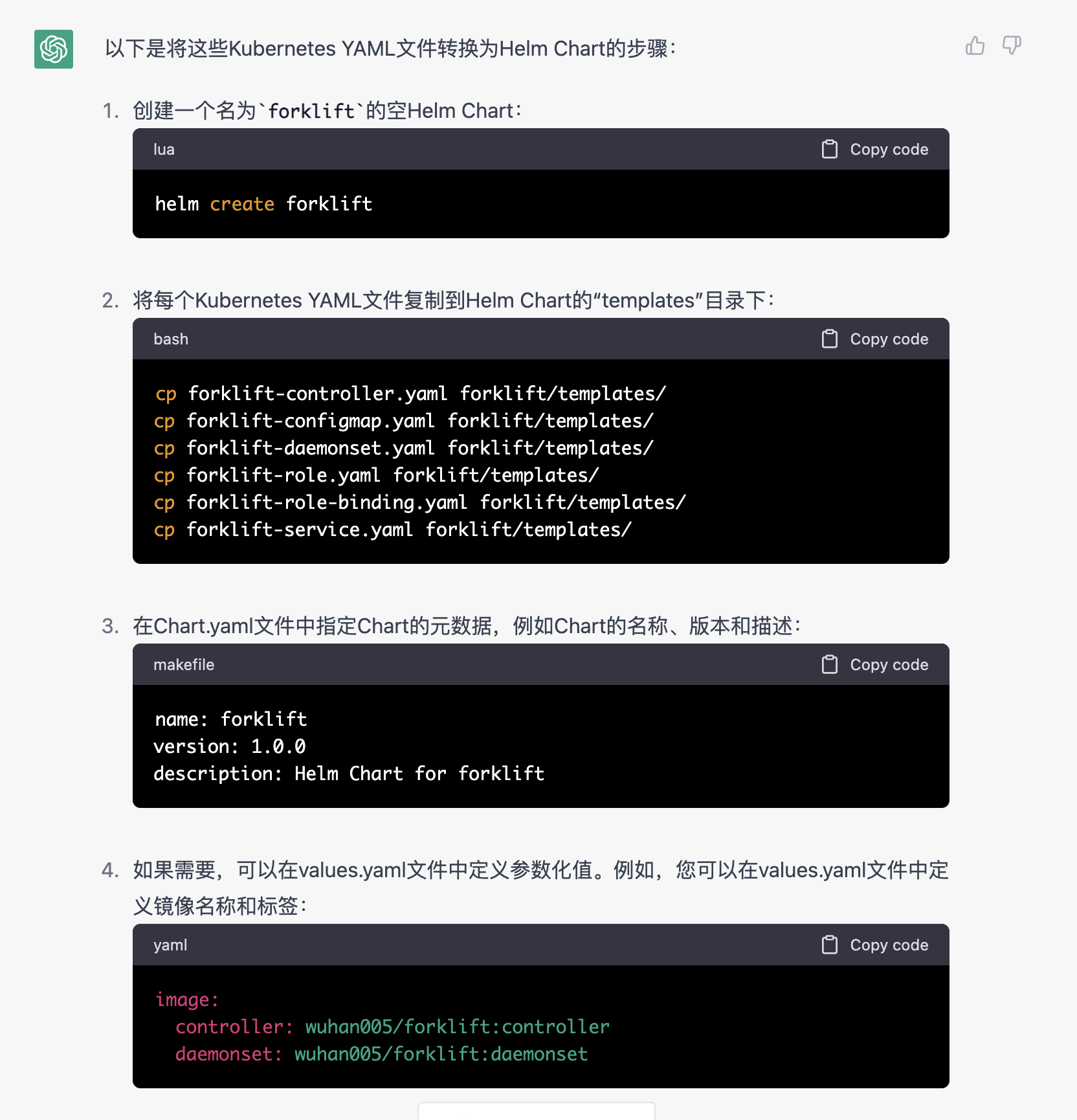
一开始它会比较笼统地告诉你创建 Chart.yaml 和 values.yaml 这两个文件:
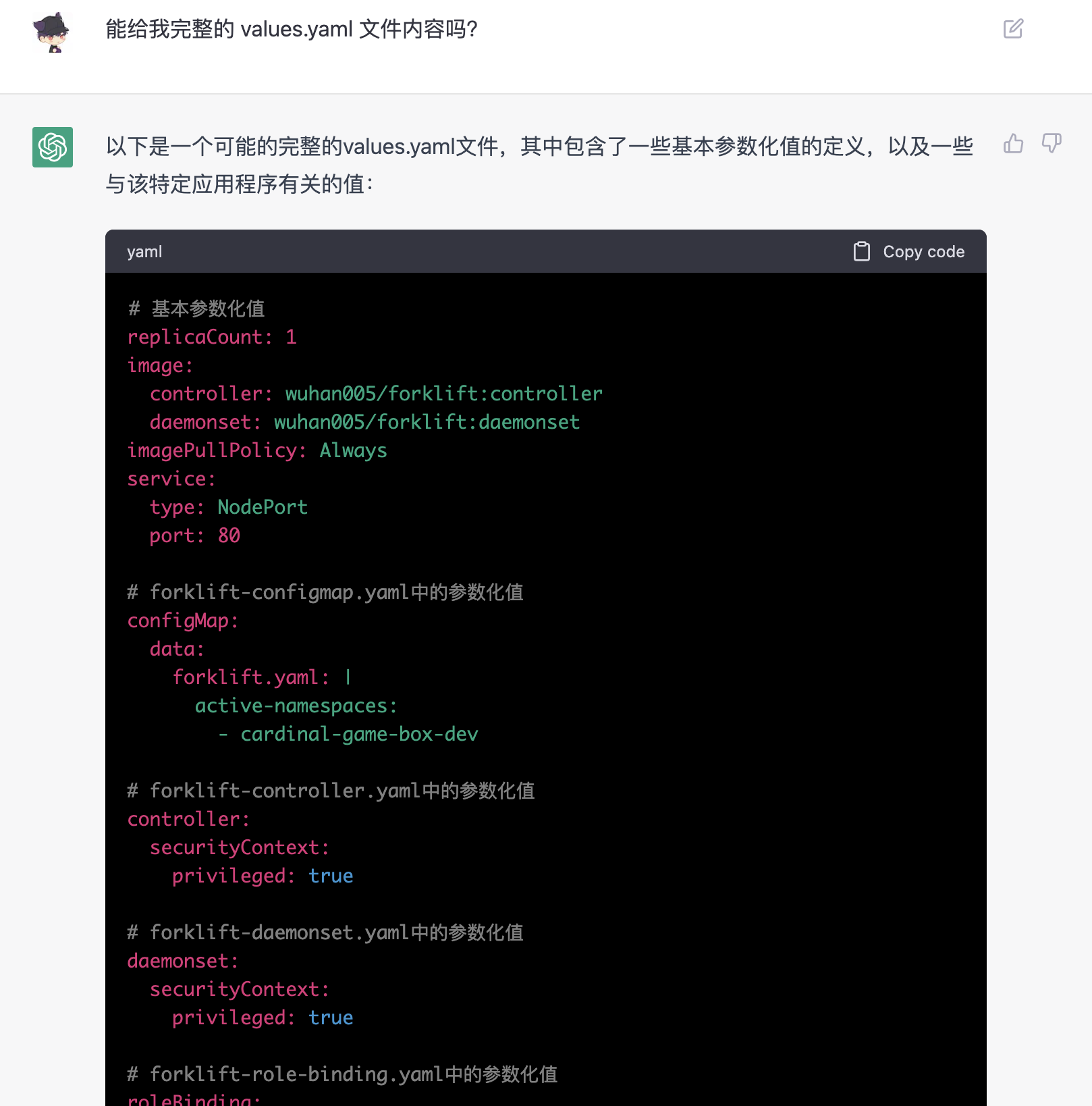
但是我们可以继续追问它,让它提供完整的 values.yaml 文件的内容,它会根据前面各种资源的 YAML 定义,比较聪明地判断出哪些是应该暴露到 values.yaml 里提供给用户自定义的。
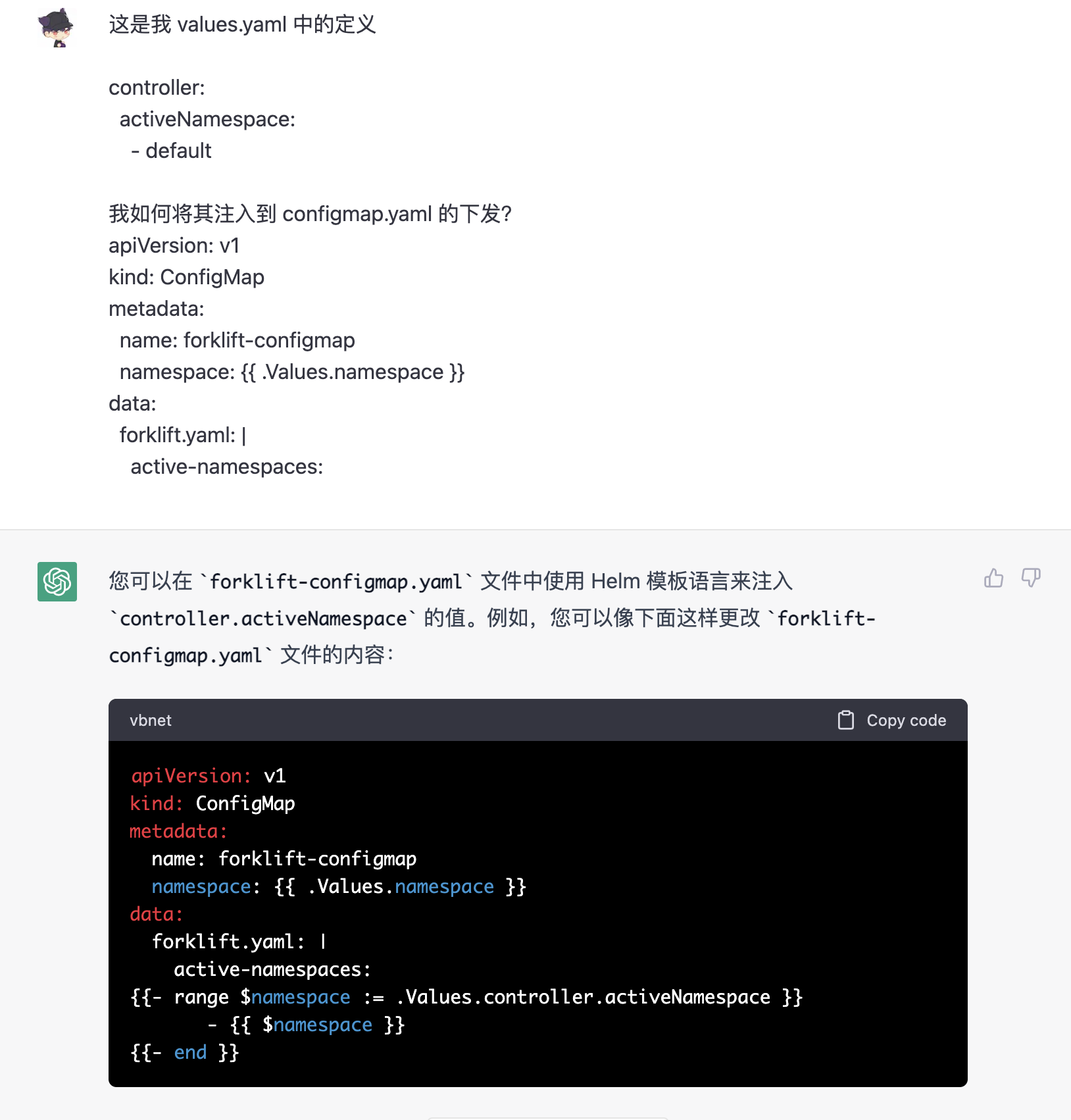
对于稍微不符合预期的结果,我们可以在自己改了一点之后,再让 ChatGPT 帮我们处理复杂的 Go 模板语言书写:
甚至最后部署到 ArgoCD 的 Application YAML,也可以让它帮你完成!真的很棒!
打包
完成了 Helm Chart 的编写后,我们可以运行下 Lint 看看是否有问题:
helm lint --strict
没问题后,那就开始打包咯~
helm package .
mv forklift-0.1.0.tgz ./charts # 移动到 charts 目录下,整齐一些
最后更新我们的 index.yaml 文件:
helm repo index .
至此,你就可以 commit + push 代码了,同时要给对应的 GitHub 仓库开启 GitHub Page。(说实话我不觉得把打包后的 .tgz 文件推上去是个好主意,或许有更好的方法?)
我们需要留意 GitHub Page 中对应指向仓库 Chart.yaml 文件的路径。我的这个 forklift 项目路径是放在 ./charts 目录下,同时我的 GitHub ID 是 wuhan005,所以当有人要拉取我的 Chart 时填写的 URL 是:
https://wuhan005.github.io/forklift/charts/
TODOs (但愿不咕)
目前我使用 ArgoCD 将 forklift 部署到了我自己的集群中,看起来还是挺稳的。以下是之后的一些 TODOs:
- 配置文件除了支持按命名空间指定外,还需要支持直接指定镜像名。
- Controller 的 HTTP 服务是否需要加个凭证鉴权?现在是集群里的其它 Pod 都能通过 Service 访问。
- Controller 所在的节点上其实没必要再部署一个 Daemonset 自己跟自己玩,纯属浪费。
- 目前配置文件是做成 ConfigMap 挂载进来的,是否考虑挂载文件卷进来,做到像 Prometheus 一样修改文件后请求指定的接口动态读取并刷新配置。
目前能想到的就是这些,如果你在使用过程中发现了什么 bug,也欢迎提 issue 反馈~ 这是我对于 K8s 镜像预热的一个很不成熟的想法,我也不知道它是否有瓶颈,目前还有待生产环境的考验。还请各位多多指点。

喜欢这篇文章?为什么不打赏一下呢?